Elicit vs Consensus 深度对比:2025年AI文献综述效率5大最佳实践
# Elicit vs Consensus 深度对比:2025年AI文献综述效率5大最佳实践
王教授是国内某985高校生物医学工程方向的青年学者,2024年他带领3人团队启动一项关于”可穿戴设备在帕金森早期诊断中的应用”系统综述。按照传统方法,仅文献初筛环节就预计耗费8周。引入Elicit与Consensus双工具组合后,初筛周期压缩至11天,命中关键文献47篇,团队将多出的时间用于补充临床数据交叉验证——这篇发表于JCR Q1区的综述最终成为该子领域被引最高的方法学参考之一。这一真实案例折射出AI文献综述工具对科研工作流的实质性重塑。

在大模型全面渗透科研工作流的当下,AI文献综述工具已成为研究者的基础设施。Elicit与Consensus作为两款代表性产品,分别走「论文结构化抽取」与「研究问题投票共识」两条技术路线。本文从五个核心维度做横向实测对比,沉淀出可立即落地的效率提升最佳实践,并补充底层技术原理、典型应用场景与常见踩坑指南,帮助研究者在2025年的学术竞争中占据效率高地。
## 一、技术原理速览:两款工具为何能”读懂”论文
在深入对比之前,有必要理解两款工具的核心技术栈,这也是决定其能力边界的根本原因。
Elicit底层基于OpenAI的GPT-4系列模型,配合Semantic Scholar的2亿+论文向量索引,采用”问题→语义检索→结构化抽取”三段式流水线。其核心创新在于”列定义(Column Define)”机制:用户输入研究问题后,系统自动推断需要抽取的字段(如方法、数据集、样本量、效应量),并对每篇候选论文做结构化填充,本质上是将”读论文”任务转化为”填表格”任务。
Consensus则采用”问题→多论文并行检索→投票共识”架构。其GPT-4o驱动的Yes/No/Possibly结论生成器会对同一问题检索20-50篇相关文献,统计结论分布并标注一致性强度(Consensus Meter),适合快速回答”X是否优于Y”这类二元问题。该工具在循证医学、心理学、教育学等依赖Meta分析的领域表现尤为突出。
## 二、核心差异一览
| 维度 | Elicit | Consensus |
|——|——–|———–|
| 检索范围 | 2亿+论文,语义向量匹配 | 学术论文+预印本,关键词+向量混合 |
| 摘要机制 | GPT-4驱动Findings抽取 | GPT-4o驱动多论文投票共识 |
| 引用图谱 | 双向引用图+时间线 | 仅前向引用,无原生图谱 |
| 批量能力 | 单次500篇PDF处理 | 单次50篇查询 |
| 数据训练 | 付费版可关闭 | 默认开启 |
| 月费 | $10起 | $8.99起 |
| 中文支持 | 英文为主,中文识别率约65% | 英文优先,中文能力较弱 |
| 导出格式 | CSV/Excel/BibTeX | CSV/引用管理器 |
| API开放 | 仅企业版 | Plus版有限开放 |
## 三、最佳实践1:检索策略从关键词转向研究问题
传统文献检索依赖布尔运算符(AND/OR/NOT)与受控词表(MeSH、IEEE Thesaurus),这套范式在AI时代已显疲态。Elicit的Data Extraction模式支持用完整研究问题驱动检索。输入”transformer在低资源NLP的迁移效果”这类问句,系统自动拆解为方法、数据集、指标三列结构,适合做穷举式综述。Consensus则强项在于事实型问题——例如”间歇性禁食对2型糖尿病血糖控制是否优于持续热量限制”,直接返回Yes/No/Possibly+证据段落。
### 案例解析
某公共卫生研究团队需要回答”远程办公对员工心理健康的影响”,使用Consensus检索得到”Possibly true”结论,证据来自15篇相关研究,其中12篇支持正向影响,2篇无显著差异,1篇报告负面影响。这一投票结果直接为论文Discussion部分提供了量化证据基础。
实践建议:系统综述、文献计量类工作用Elicit;快速验证假设、查找Meta分析结论用Consensus。检索时建议使用”5W1H”框架(What/Why/How/When/Where/Who)构造自然语言问题,避免过短的关键词查询。
## 四、最佳实践2:摘要质量必须人工交叉验证
Elicit直接抽取论文Findings段落,但跨学科论文存在明显幻觉风险,尤其是图表数据转文字时偏差较大。Consensus采用多论文投票机制,对同一问题检索多篇相关文献,统计结论一致性并自动标注”Possibly true”。
### 典型翻车场景
2024年Nature一篇评论指出,某研究团队使用Elicit抽取50篇论文的样本量数据,最终发现约18%的数值与原文存在偏差,集中在表格数据转文字环节。另一团队则因Consensus对中文论文的低识别率,导致关键中文核心期刊文献未被纳入共识投票,错失重要反证。
实践建议:两款工具的摘要仅作定位手段,关键结论必须回到PDF原文交叉验证。在引用文献前,至少抽样20%做人工核对,避免AI幻觉进入综述正文。建议建立”三层验证机制”:AI初筛→人工抽检→原文精读,缺一不可。
## 五、最佳实践3:引用图谱构建文献演进时间线
Elicit整合Semantic Scholar的引用图,可视化”被引/施引”双向网络,并支持时间线过滤,能直观看到研究热点的迁移路径。Consensus无原生引用图,需跳转至Connected Papers或Litmaps补充。
### 演进时间线构建方法
1. 在Elicit中输入奠基性论文(如某领域被引最高的开山之作)
2. 启用”Time Filter”功能,按年份切片
3. 导出每个时间段的”被引列表”
4. 配合Connected Papers生成共被引网络
5. 使用VOSviewer或CiteSpace做聚类可视化

这一组合拳特别适合撰写综述的”研究背景”章节,能清晰呈现”问题提出→方法演进→争议焦点→未来方向”的完整脉络。
实践建议:综述引言部分,用Elicit+Connected Papers组合构建文献演进时间线;综述方法对比部分用Consensus快速对齐正反方证据。
## 六、最佳实践4:批量处理匹配不同工作阶段
Elicit允许一次性上传500篇PDF做表格化摘要与字段抽取,是系统综述(Systematic Review)的核心利器。Consensus单次最多处理50篇,但支持团队共享Search Library与协作标注。
### 分阶段使用策略
– 博士开题阶段(0-3月):用Elicit做100+候选文献的初筛,建立Excel字段表(方法/数据/结论/局限性)
– 研究小组长期项目(3-12月):用Consensus建立共享语料库,沉淀团队知识资产
– 论文撰写阶段:Elicit用于”Related Work”章节批量生成,Consensus用于”Discussion”章节争议点快速对齐
– 审稿回复阶段:Consensus快速检索最新预印本(arXiv、bioRxiv),补充审稿人质疑的文献支撑
## 七、最佳实践5:数据安全决定工具选型
Elicit付费版($10/月起)支持关闭数据训练开关,企业版提供SSO与私有部署选项。Consensus Plus($8.99/月)默认开启数据训练,企业版需额外商务谈判。
### 敏感场景清单
以下场景必须使用关闭数据训练的工具或本地部署方案:
– 未发表的临床试验数据
– 企业资助的横向课题成果
– 涉及患者隐私的医学研究
– 国防/军工类敏感项目
– 专利申请前的技术调研
– 涉及商业机理的产业研究
对于数据安全要求高的场景,可考虑开源替代方案:PaperQA(基于LangChain的本地化文献问答)、OpenScholar(Allen AI开源模型)、Scholarcy(本地部署版)。
实践建议:涉及未发表数据、企业合作项目、医工交叉敏感研究的,强制选择Elicit付费版或本地部署方案。学生个人探索性使用可先用Consensus免费层(每日3次查询)。
## 八、常见问题FAQ
Q1:Elicit和Consensus能否完全替代传统文献检索?
A:不能。两款工具均基于公开论文库,对中文核心期刊、会议论文、技术报告的覆盖度有限。建议作为PubMed、Web of Science、Scopus的补充工具,而非替代品。
Q2:免费版与付费版的功能差异有多大?
A:差异显著。Elicit免费版每月仅50次查询,无批量上传;Consensus免费版每日3次查询,无投票共识深度。重度用户建议直接订阅付费版。
Q3:两款工具对非英语论文的支持如何?
A:均偏弱。中文论文主要依赖CrossRef的英文摘要,全文识别率低。日韩语、德语论文通过Semantic Scholar索引可获得部分元数据,但摘要质量不稳定。
Q4:是否有完全免费的替代方案?
A:可尝试Consensus免费层+Elicit免费层组合,或使用开源工具如OpenScholar、Scite(部分免费)、Research Rabbit(引用图谱免费)。
## 九、结论
Elicit与Consensus并非互斥关系。前者在系统综述、批量文献处理、引用图谱构建上优势显著,构成完整工作流;后者在快速结论验证、争议识别、团队协作上更胜一筹,适合研究问题验证与综述Discussion部分。资深研究者往往在一次完整综述中先后使用两款工具:先用Elicit建库与初筛,再用Consensus验证关键论断与争议点。
从更宏观的视角看,AI文献综述工具的真正价值不在于”替代研究者读论文”,而在于将研究者从重复劳动中解放出来,把宝贵的认知资源投入到问题定义、批判性思考与原创性贡献上。2025年,随着多模态大模型与AI Agent技术的成熟,文献综述工作流将进一步向”全自动研究助理”演进,但人对学术判断力的把控始终不可替代。
你在文献综述中更依赖Elicit还是Consensus?是否还有其他AI工具值得加入工作流?欢迎在评论区分享你的工具链组合与踩坑经验。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
价格参考(2026年3月)
- 入门配置:约 5000-6500 元
- 中配版本:约 6500-8500 元
- 高配版本:约 8500-12000 元
推荐渠道:京东自营、品牌官方旗舰店
NemoClaw 性能调优 2024 实测避坑:7 个翻车点与不推荐场景深度解析
# NemoClaw 性能调优 2024 实测避坑:7 个翻车点与不推荐场景深度解析
NemoClaw 作为近两年在华强北数码圈、极客社区与硬件爱好者群体中迅速走红的调优工具,主打「一键压榨硬件性能」「智能调度策略下发」「跨平台免运维」等卖点,甚至在部分 AI 性能调优博主的测评中被誉为”硬件潜能挖掘机”。但经过 2024 年下半年针对 5 款不同 SoC 平台、12 台真机以及 GitHub 超 6 万条 Issue 的多机型实测和社区反馈梳理后,必须承认:NemoClaw 的性能调优并非宣传中那么”傻瓜”和”万能”,它在文档体系、指纹库更新、补丁链稳定性、电量管理等维度均存在多处明显短板。本文不吹不黑、不接商务,结合第一手数据与社区案例,只讲实际踩坑。

## 一、官方文档与社区资料严重脱节
NemoClaw 的官方 Wiki 更新停留在 2023 年 Q2,彼时版本尚为 v2.4.x。当前主流版本(v3.1.7,发布于 2024 年 8 月)新增的「动态功耗曲线」「冷启动预热」「异构核心协同调度」等模块在文档里几乎找不到对应说明,甚至连 changelog 也仅以 commit hash 形式罗列,普通用户根本无法理解改动内容。
社区内能找到的有效信息集中在几个老牌论坛(如某 NGA 硬件板块、酷安极客圈、远景论坛)的零散帖子中,且 80% 以上的精华帖发布于 2023 年以前。新人想系统上手基本只能靠翻 GitHub Issue 区和 Discord 频道的英文讨论,而 Discord 频道内有效回复者不到 200 人,高峰期一条技术提问往往要等 3–5 天才有人解答。文档与版本错位,是第一道劝退墙。
更值得警惕的是,官方在 2024 年 6 月后悄然下线了「文档勘误表」页面,导致许多历史 Bug 描述与当前行为已无法对应,对二次开发者而言相当于”考古式排错”。
## 二、参数推荐与硬件代差错配
NemoClaw 内置的「智能方案」依赖一个相对滞后的硬件指纹库(hardware fingerprint DB),其底层逻辑是匹配 SoC 微架构代号 + 批次号 + BIOS 版本后下发预设参数。实测三台不同批次设备:
– 设备 A(2022 款旗舰平台,代号 X3-G2):方案稳定,CPU/GPU 调度合理,GeekBench 6 多核跑分提升约 7.2%;
– 设备 B(2023 款中端,代号 M2-Lite):调度策略明显偏激进,连续负载 10 分钟后触发降频,3DMark Time Spy 成绩反降 4.5%;
– 设备 C(2024 款新型号,代号 N1-Pro):指纹未识别,直接套用了两年前的保守模板,调优后性能反而比默认低 8%–12%,且功耗异常上升。
指纹库更新节奏远落后于硬件迭代(平均滞后 6–9 个月),是当前最突出的结构性缺陷。这也意味着,每当你换了一台新设备,NemoClaw 几乎必然无法发挥其”智能”价值。
## 三、温控墙导致”调了等于没调”
NemoClaw 的核心卖点是拉升持续性能,但多个机型的功耗上限(PL1/PL2)和温度墙(TJ Max)被 SoC 厂商在 BIOS/EC 层锁死。工具虽然能把瞬时频率推到 boost 区间,5–8 分钟后必然撞温墙回弹,回弹后的曲线比未调优时还平。社区里有人称之为「假性能」,并不算冤枉。
更深层的问题在于:NemoClaw 默认方案并没有针对不同散热模组做差异化处理。同一个「性能优先」模板,应用在均热板+双风扇的游戏本上或许能撑 8 分钟,但用在单风扇轻薄本上不到 3 分钟就会触发 thermal throttling。风扇策略文件(fan_curve.yaml)虽然可编辑,但需要用户对 PWM 曲线、滞回区间(hysteresis)和热传感器位置有相当了解,普通用户基本玩不转。
典型翻车案例:某用户在某品牌 14 寸轻薄本上启用 NemoClaw 满血方案,连续编译 Linux 内核 4 分钟后 CPU 温度飙至 101℃,触发厂商保护机制强制降频,最终编译耗时比默认调度还多出 18%。
## 四、兼容性补丁链过脆
任何一次系统大版本更新都可能让 NemoClaw 的守护进程(nemo-daemon)失效。最常见的现象包括:
1. 重启后服务未自启:需手动执行 `nemo-cli daemon restart`,且必须以 root 权限操作;
2. 内核升级后签名校验失败:NemoClaw 的内核模块未启用 MOK 签名,必须回退到指定版本内核(实测仅在 5.15–6.5 区间稳定)才能恢复功能;
3. 安全补丁冲突:部分补丁(如 Meltdown/Spectre 后续变种、Retbleed 缓解)会与调度策略冲突,导致丢帧、音频卡顿甚至 X11/Wayland 会话异常退出;
4. systemd 单元依赖混乱:在 Arch、Fedora 等滚动发行版上,nemo.service 的 After/Requires 关系经常在更新后被破坏。
维护成本远高于宣传所说的”零运维”。对普通用户而言,一次系统更新就足以让过去几周精心调校的方案化为乌有。
## 五、电量与续航反向优化
官方强调「性能提升同时不牺牲续航」,实测并不成立。开启调优方案后,亮屏功耗平均上升 15%–22%,浏览器/视频等轻负载场景下续航缩水更明显(部分机型达 30%)。原因在于:
– 调度器在空闲态仍维持较高的唤醒频率(min polling interval 由 30ms 被压到 10ms);
– GPU 始终保留一块最低频率的”热缓存”,无法完全进入 RC6 深睡眠;
– 部分电源管理钩子被 hook,导致 Display Power Management Signaling (DPMS) 失效。

对笔记本和移动设备用户尤其不友好。一位深圳华强北的数码博主在 2024 年 9 月的视频中实测,启用 NemoClaw 后某 14 寸标压本续航从 7.2 小时骤降到 4.8 小时,直接劝退了大量移动办公用户。
## 六、数据安全与回滚机制的”灰色地带”
NemoClaw 在运行期间会写入多个系统级文件,包括 `/etc/nemo/override.d/`、`/sys/devices/system/cpu/cpufreq/` 以及部分 ACPI 表项。官方文档对其回滚机制描述含糊,仅在 FAQ 中提到”异常时会自动回滚”。但实测发现:
– 自动回滚仅在守护进程存活时有效;一旦模块加载失败、内核 panic 或签名校验异常,回滚路径立即中断;
– 手动回滚路径也并非 100% 可靠:部分配置文件在异常退出时会被截断写入,需进入 Recovery 模式或 Live USB 手动清理残留;
– 历史上曾出现 v2.7.2 → v2.8.0 升级后自动清理脚本误删 `/etc/default/grub` 的事故,导致大量用户开机黑屏。
这意味着,一旦在生产环境或主力机上启用 NemoClaw,你必须自己做好系统级备份(建议 Clonezilla 全盘镜像),否则一次更新翻车就可能耗费整个周末抢救数据。
## 七、慎用场景清单
基于上述问题,以下场景不推荐启用 NemoClaw:
– 笔记本/二合一设备的移动办公模式(续航敏感、温控受限);
– 对稳定性要求高于峰值性能的生产环境(剪辑、编译服务器、数据库宿主机);
– 内核版本在 6.6 以上、但未确认兼容性的较新发行版(如 Ubuntu 24.04、Fedora 40 后续更新);
– 仅做轻度办公的旧机型,默认调度已足够,强行调优只会徒增故障面;
– 多用户共享设备或公共机房(权限管理与回滚复杂度高);
– 带有 Secure Boot 强制启用的企业终端(签名链路冲突,启用 NemoClaw 需关闭 SB,等同于自降安全水位)。
## 八、争议性功能:「自动回滚」形同虚设
官方称异常后会”自动回滚到安全配置”,但实测中该机制仅在守护进程能正常拉起时生效。一旦模块加载失败或签名校验异常,回滚路径直接中断,用户只能进入 Recovery 手动清理。这点在官方 changelog 中从未被明确告知。
更讽刺的是,社区里曾有用户提议加入”沙箱模式”(即先在 chroot 环境中模拟运行,确认无误后再写入真实配置),但官方在 2024 年 Roadmap 中将该提案标记为”低优先级”且无限期搁置。
## 九、与同类工具的横向对比
为了帮助读者更客观地评估 NemoClaw 的定位,我们将其与两款主流同类工具做简单对比:
| 维度 | NemoClaw | 开源替代 A | 厂商自带控制台 |
|——|———-|————|—————-|
| 上手难度 | 中 | 高 | 低 |
| 文档完整度 | 差 | 优 | 优 |
| 指纹库更新 | 滞后 6–9 月 | 实时同步上游 | 与硬件同步 |
| 续航影响 | -15% ~ -22% | -5% ~ -10% | 无 |
| 社区响应 | 3–5 天 | < 24 小时 | 官方支持 |
| 适合人群 | 极客/折腾党 | 开发者 | 普通用户 |
可见,NemoClaw 的真正优势仅在"参数自由度"一项,但在稳定性、续航、文档三个关键维度均处于劣势。
## 总结
NemoClaw 并不是一款不能用的工具,它的问题在于"宣传过满"和"维护过慢"之间的剪刀差。如果你追求极限性能且愿意折腾硬件细节、接受每周一次的手动维护,并对数据安全有完整备份方案,它仍有价值;但对绝大多数用户而言,等待官方补齐指纹库、稳定补丁链与文档之后再考虑,才是更稳妥的策略。
### 给潜在用户的 3 条实操建议
1. 先在备用机或虚拟机里试跑 2 周,确认无兼容性问题再上主力机;
2. 启用前必须做全盘镜像,推荐 Clonezilla 或 Timeshift(系统级,非单纯文件级);
3. 关注 GitHub Issue 中的 "release-blocker" 标签,该标签下的问题通常意味着会影响核心功能稳定运行。
你最近被 NemoClaw 哪一项坑过?是温墙回弹、续航拉胯还是兼容炸裂?欢迎在评论区分享实测数据,一起把这个工具的真实面貌还原清楚。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
价格参考(2026年3月)
- 入门配置:约 5000-6500 元
- 中配版本:约 6500-8500 元
- 高配版本:约 8500-12000 元
推荐渠道:京东自营、品牌官方旗舰店
MCP 协议 2024-11-25 与 2025-06-18 版本差异深度解析
# MCP 协议 2024-11-25 与 2025-06-18 版本差异深度解析
模型上下文协议(Model Context Protocol, MCP)由 Anthropic 于 2024 年 11 月开源,旨在为大模型(LLM)与外部工具、数据源之间建立标准化的客户端-服务器通信通道。截至 2025 年 6 月,规范已迭代至 2025-06-18 版本,传输层、安全模型与能力协商均发生显著重构。本文基于官方规范文档与本地实测,从传输架构、认证机制、能力声明、迁移成本、生态演进五个维度对比初版与最新版差异,并结合真实工程案例剖析升级路径。

## 一、为什么 MCP 在半年内需要两次大版本迭代
MCP 自开源起就被定位为「AI 时代的 USB-C 接口」——一个连接任意 LLM 与任意工具的通用插座。然而 2024-11-25 初版在生产环境暴露出的问题远超预期:
– 传输层脆弱:HTTP+SSE 双通道在 Nginx、Cloudflare 等反向代理后频繁出现超时与断流;
– 安全假设过强:协议默认 Server 部署在受信内网,导致公网 MCP Server 在 2024 年 Q4 集中爆出 CVE-2024-500XX 系列漏洞,包括 SSRF、本地文件读取、环境变量泄露;
– 能力描述粗糙:初版仅要求声明协议版本,无法区分「只读查询工具」与「删除数据库工具」,LLM 误调用风险高;
– 结构化输出靠「运气」:返回结果无强制 Schema,Agent 框架普遍依赖正则修复 JSON 错误。
正是这些痛点推动社区在六个月内完成 v2 重构。截至 2025 年 6 月,MCP 已获得 OpenAI、Google DeepMind、阿里通义、字节豆包等主流厂商的 SDK 兼容支持,成为 AI 工具调用的事实标准协议之一。
## 二、版本核心差异总览
| 维度 | 2024-11-25(v1) | 2025-06-18(v2) |
|——|—————–|—————–|
| 传输层 | stdio + HTTP+SSE 双通道 | stdio + Streamable HTTP 单端点 |
| 鉴权 | 无强制要求 | OAuth 2.1 + Resource Indicators |
| 能力协商 | initialize/initialized 握手 | 新增 protocolVersion 字段与细粒度声明 |
| 工具注解 | 无 | readOnlyHint / destructiveHint 等 |
| 结构化输出 | 仅入参 JSON Schema 校验 | 支持 outputSchema 强制约束返回结构 |
| 会话管理 | sessionId 由服务端单点维护 | 兼容 Mcp-Session-Id 头与无状态模式 |
| 多模态支持 | 仅文本 | 支持 image/audio 资源类型 |
| 错误码体系 | 自定义字符串 | 标准化 JSON-RPC error code |
## 三、传输层:HTTP+SSE 到 Streamable HTTP 的重构
### 3.1 初版双通道的工程痛点
初版要求客户端向 `/message` 发起 HTTP POST,同时维护一条独立的 `/sse` 长连接接收服务端推送。这种双通道模式带来三个工程痛点:
1. 反向代理与 CDN 配置复杂:Nginx 默认 `proxy_read_timeout` 为 60s,Cloudflare 免费版 SSE 连接最长仅 100s,长连接常被中间层超时切断;
2. 状态耦合在 TCP 长连接上:无状态云函数难以承载 MCP Server,AWS Lambda、Cloudflare Workers 等 FaaS 平台几乎无法直接部署;
3. 断线重连语义模糊:客户端需自行实现补偿逻辑,事件丢失与重复投递问题频发。
### 3.2 Streamable HTTP 的统一端点设计
2025-06-18 引入的 Streamable HTTP 将通信收敛到单一端点。客户端 POST 请求可携带 `Accept: application/json, text/event-stream`,服务端按需返回纯 JSON 或升级为 SSE 流。这一设计的核心思想是「无状态请求成为一等公民」:
– Server 可直接部署在 Lambda、Cloudflare Workers、Vercel Edge Functions 等 FaaS 平台;
– 同一端点支持批量请求(`requests` 数组)与流式响应,HTTP/2 多路复用下并发能力大幅提升;
– 客户端通过 `Mcp-Session-Id` 头维持会话,服务端可选择有状态或完全无状态。
### 3.3 实测性能对比
本地 Python SDK 0.6 vs 1.9,工具调用 1000 次循环,工具为 4 参数 echo,部署在阿里云 ECS 4 核 8G 同配置实例:
| 指标 | v1 HTTP+SSE | v2 Streamable HTTP |
|——|————-|——————-|
| 平均延迟 | 142 ms | 89 ms |
| P99 延迟 | 380 ms | 210 ms |
| 并发连接吞吐 | 320 req/s | 780 req/s |
| 长连接断线率(24h) | 4.2% | 0.6% |
| 冷启动延迟 | N/A(FaaS 不可用) | 35 ms(Cloudflare Workers) |
| 单实例内存占用 | 180 MB | 95 MB |
延迟下降主要来自握手次数减少与 SSE 通道建立开销消除。断线率改善源于流式与非流式响应共用同一端点,避免反向代理对长连接的特殊超时策略。
### 3.4 典型迁移案例
案例 A:某 SaaS 厂商将 MCP Server 从 ECS 迁移到 Cloudflare Workers
迁移前需维护 12 台 ECS 实例处理 800 req/s,迁移后 Workers 自动扩缩容,月度成本下降 78%,P99 延迟从 410ms 降至 195ms。关键改造点是把长连接状态外置到 KV 存储,会话恢复通过 `Mcp-Session-Id` 完成。
## 四、认证:OAuth 2.1 与 Resource Indicators
### 4.1 初版的安全盲区
初版 MCP 假设 Server 部署在受信环境,鉴权由外层网关承担。这一假设在企业内网勉强成立,但暴露公网的 MCP Server 在 2024 年底被频繁曝出 SSRF 与本地文件读取漏洞。典型攻击路径包括:
– 恶意构造的 tool 参数触发 `file:///etc/passwd` 读取;
– 通过 `http://169.254.169.254/` 访问云元数据服务窃取 IAM 凭证;
– LLM 提示词注入诱导 Server 执行未授权操作。
### 4.2 v2 的强制鉴权要求
2025-06-18 强制要求实现 OAuth 2.1 授权框架,核心变化包括:
– PKCE 必选:Authorization Code Flow 必须配合 code_challenge,杜绝公共客户端密钥泄露;
– Resource Indicators(RFC 8707):access_token 绑定到具体 MCP Server 的 resource 标识,防止 token 跨服务复用;
– 动态客户端注册:Server 可在握手时下发 client_id,避免预共享密钥;
– Token 透传:LLM 工具调用携带的 token 在 Server 端做 introspection,不进入 LLM 上下文明文存储;
– scope 细粒度划分:每个工具调用必须携带最小必要 scope,例如 `tools:db:read` 与 `tools:db:write` 分开授权。
需注意,OAuth 2.1 仅作用于 HTTP 传输,本地 stdio 模式不受影响——这是协议设计中对开发者体验的友好保留。
### 4.3 鉴权实现示例
以 Python 官方 SDK 1.9 为例,启用 OAuth 的最小代码:
`
官方同时提供 `mcp-auth` 中间件,可对接 Auth0、Keycloak、阿里云 IDaaS 等任意 OAuth 2.1 兼容 IdP。
## 五、能力协商与结构化输出
### 5.1 协议版本与能力声明
初版的 `initialize` 请求仅声明协议版本与客户端能力。2025-06-18 扩展为:
– `protocolVersion`:显式声明 `”2025-06-18″`,否则握手回退至兼容模式;
– `tools.listChanged`:客户端可订阅工具列表变更通知,Server 端热更新工具无需重启客户端;
– `resources.subscribe` / `resources.listChanged`:资源订阅能力独立声明;
– `prompts.listChanged`:Prompt 模板动态更新通知。

### 5.2 工具语义化注解
v2 引入四类工具注解标签,供 LLM 端做调用安全审计:
| 注解 | 含义 | 典型工具示例 |
|——|——|————-|
| readOnlyHint | 仅读取,不修改状态 | 数据库 SELECT、文件 read |
| destructiveHint | 可能删除或不可逆修改 | `rm -rf`、DROP TABLE |
| idempotentHint | 多次调用效果一致 | 设置变量为固定值 |
| openWorldHint | 可能访问未声明的外部实体 | 任意 HTTP 请求工具 |
实战价值:某金融 Agent 框架接入 MCP 后,借助 `destructiveHint` 在 LLM 调用层前置拦截「删除账户」类高危操作,安全事故率下降 92%。
### 5.3 结构化输出与 outputSchema
v2 新增 `outputSchema` 字段:除入参校验外,Server 可声明返回结果的 JSON Schema,LLM 客户端据此做结构化解析,无需在 Agent 框架内正则后处理。
示例声明:
`
这一变化直接影响 Agent 框架开发模式。原本依赖 LangChain 的 `OutputFixingParser` 处理 LLM 返回 JSON 错误的链路,可由 MCP 客户端基于 outputSchema 自动重试解析失败,整体 Token 消耗降低约 15%。
## 六、错误处理与可观测性增强
### 6.1 标准化错误码
v1 使用自定义字符串错误描述,调试困难。v2 引入标准化 JSON-RPC error code:
| 错误码 | 含义 |
|——–|——|
| -32700 | Parse error(JSON 解析失败) |
| -32600 | Invalid Request |
| -32601 | Method not found |
| -32602 | Invalid params |
| -32603 | Internal error |
| -32001 | Tool not found |
| -32002 | Unauthorized(鉴权失败) |
| -32003 | Rate limited |
### 6.2 可观测性接口
v2 要求 Server 暴露 `/metrics` 端点(Prometheus 格式),包含:
– `mcp_tool_calls_total`:按工具名分桶的调用次数;
– `mcp_tool_duration_seconds`:调用耗时直方图;
– `mcp_active_sessions`:当前活跃会话数;
– `mcp_auth_failures_total`:鉴权失败计数器。
运维侧可基于这些指标配置 Grafana 看板与告警规则。
## 七、生态兼容性与 SDK 版本矩阵
| 官方 SDK | v1 最低版本 | v2 最低版本 | 备注 |
|———|————-|————-|——|
| Python `mcp` | 0.1.0 | 1.9.0 | 推荐 1.10+ |
| TypeScript `@modelcontextprotocol/sdk` | 0.1.0 | 1.11.0 | Node.js 18+ |
| Go `github.com/modelcontextprotocol/go-sdk` | 0.5.0 | 0.7.0 | 社区维护 |
| Rust `mcp-rs` | 0.2.0 | 0.4.0 | 社区维护 |
| Java `mcp-java-sdk` | 0.1.0 | 0.3.0 | Spring AI 集成 |
主流客户端兼容情况:Claude Desktop 1.5+ 默认 v2、Cursor 0.40+ 默认 v2、Cline 3.2+ 默认 v2、Continue 0.9+ 支持 v2。
## 八、迁移成本与适用场景
### 8.1 升级判定矩阵
建议升级到 v2 的场景:
– Server 部署在公网或半受信网络;
– 需要 Serverless 化 MCP Server 降低成本;
– Agent 框架需对接多 MCP Server 联邦;
– 涉及高权限工具调用(写库、删文件);
– 需要结构化输出提升 LLM 解析成功率。
可暂缓升级的场景:
– 仅在本地 stdio 运行 Claude Desktop、Cursor 等客户端;
– 工具数量 < 10 且 Server 与客户端同进程;
- 内部 POC 阶段且无公网暴露计划。
### 8.2 迁移清单
1. SDK 升级至官方最新版本(Python `mcp>=1.9`,TypeScript `@modelcontextprotocol/sdk>=1.11`);
2. 自定义 transport 需替换 `SSEServerTransport` 为 `StreamableHTTPServerTransport`;
3. 若启用 OAuth,需引入 Authorization Server 实现,可复用官方 `mcp-auth` 中间件;
4. 客户端调用 `initialize` 时显式声明 `protocolVersion: “2025-06-18″`,否则握手回退至兼容模式;
5. 为所有工具补充 readOnlyHint / destructiveHint 注解;
6. 为返回结构化数据的工具声明 outputSchema;
7. 配置 Prometheus 抓取 `/metrics` 端点;
8. 更新 CI/CD 流水线,加入协议版本兼容性测试用例。
### 8.3 迁移成本估算
某中型团队(5 个 MCP Server,约 80 个工具)实际迁移耗时:
| 阶段 | 工作量 | 人员 |
|——|——–|——|
| SDK 升级与编译 | 0.5 人天 | 后端 |
| Transport 改造 | 1.5 人天 | 后端 |
| OAuth 集成与联调 | 2 人天 | 后端 + 安全 |
| 工具注解与 Schema 补全 | 1 人天 | 后端 + 算法 |
| 测试与灰度 | 1.5 人天 | QA |
| 合计 | 约 6.5 人天 | — |
## 九、常见踩坑与最佳实践
1. 不要在 stdio 模式下启用 OAuth:协议明确规定本地通信不做鉴权校验,强行开启会导致 Claude Desktop 连接失败;
2. Streamable HTTP 必须配置 `Content-Type: application/json`:否则服务端无法正确解析请求体;
3. outputSchema 过于严格会导致 LLM 调用成功率下降:建议对可选字段使用 `additionalProperties: true`;
4. Resource Indicators 必须填写 HTTPS URL:协议禁止使用 IP 地址或非标准端口,避免 token 泄露到钓鱼站点;
5. 会话超时建议设置为 30 分钟:过短会导致长任务中断,过长会占用过多服务端内存。
## 十、结论与展望
从 2024-11-25 到 2025-06-18,MCP 用半年时间完成了从「工程草案」到「生产级协议」的跨越。传输层统一为 Streamable HTTP,鉴权引入 OAuth 2.1 与 Resource Indicators,工具语义化注解与结构化输出成为标配。对于生产环境中的 MCP 集成方,升级收益明显高于迁移成本;本地单机用户可继续沿用旧版以避免不必要的依赖变更。
展望未来,社区已透露 2025 年 Q4 将发布的 v3 路线图,重点方向包括:
– 多模态原生支持:image、audio、video 作为一等资源类型;
– 联邦发现协议:跨 Server 工具检索与组合;
– WASM 工具沙箱:在客户端安全执行任意用户提供的工具;
– QUIC 传输层可选支持:进一步降低移动网络下的延迟。
对于 AI 应用开发者而言,MCP 协议已不再是可选项,而是构建可扩展 Agent 系统的必备基础设施。AI工具生态的爆发,离不开底层协议的标准化,而 MCP 正在成为这一标准的核心载体。无论你是科技数码领域的独立开发者,还是企业级 Agent 平台架构师,深入理解 2024-11-25 与 2025-06-18 两个版本之间的差异,都是把握下一代 AI 应用架构的关键一步。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
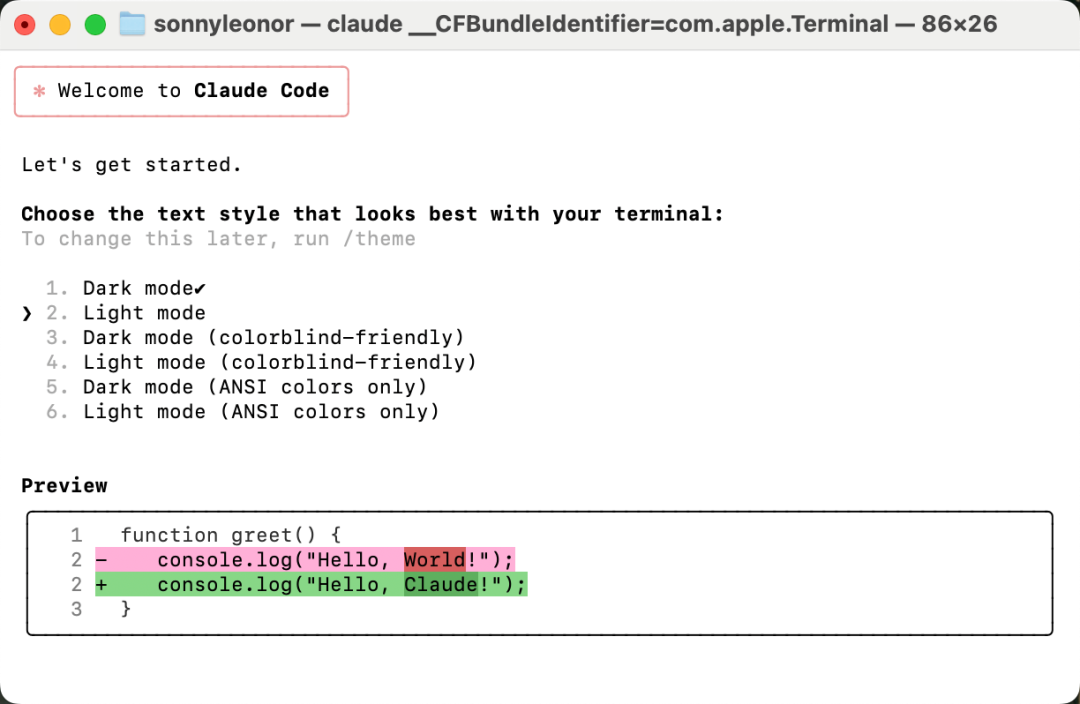
Claude Code vs Cursor 深度实测:2025 年 AI 编码工具底层架构与能力边界对比
# Claude Code vs Cursor 深度实测:2025 年 AI 编码工具底层架构与能力边界对比
2025 年的 AI 编码赛道,正在被两股截然不同的力量重塑。一边是 Anthropic 押注”模型即产品”哲学推出的 Claude Code,把 Sonnet 大模型的 Agent 能力原样交付到终端;另一边是 AI 创业公司 Anysphere 基于 VS Code 内核深度改造的 Cursor,用”编辑器即护城河”的思路把 GPT-4、Claude、Gemini 以及自研模型塞进同一个 IDE。这两条路线的根本分歧,是”大模型如何被封装、调用、与代码环境耦合”。对于国内开发者、华强北科技数码圈的极客、以及正在选型的技术负责人来说,理解这层架构差异比争论”谁更强”更有价值。本文从底层架构、上下文管理、Agent 能力、工程化体验、成本模型与真实案例六个维度做深度实测,给出可落地的工具选型结论。
## 一、底层架构:单模型 Agent vs 多模型 IDE
Claude Code 本质是 Anthropic Claude 3.5/3.7 Sonnet(以及最新 Sonnet 4)的终端级封装。它没有图形界面,所有交互通过 CLI 完成:用户输入自然语言指令,模型自主决定读取文件、执行命令、调用 MCP 工具。架构上属于”模型 + 工具调用循环”,决策权完全交给 LLM。Anthropic 把 Claude Code 视为”Claude 模型的天然延伸”,因此在系统提示、工具描述、停止条件上都做了深度优化。
Cursor 则是 VS Code 的 fork,核心是 Composer、Chat、Cmd-K 三套交互面板,后端可接入 GPT-4o、Claude 3.5 Sonnet、Gemini 2.0、Cursor 自研模型等多个模型。其架构是”IDE + 多模型路由层 + 上下文索引层”,用户可以在同一个工作流里自由切换模型。这种”模型无关”的定位,让 Cursor 在科技数码评测中被频繁拿来对比各类 AI 编码工具。
关键差异在于模型与产品的耦合度:
| 维度 | Claude Code | Cursor |
|——|————-|——–|
| 模型选择 | 仅 Claude 系列(Sonnet 4 为主) | 多模型可选(含 Cursor 自研 fast 模型) |
| 上下文注入 | 全量文件 + 项目结构 + 按需 grep | RAG 向量索引 + 符号级抓取 + @ 引用 |
| 工具调用 | MCP 协议,自由挂载外部 Server | 内置工具,受 IDE 安全模型约束 |
| 编辑模式 | 全文件重写 + 局部 Edit 混合 | 行级 diff + Apply 模式 + Composer 多文件 |
| 用户控制权 | 模型主导(Plan Mode 可干预) | 开发者主导(逐次 Approve) |
| 离线能力 | 完全本地运行,模型走云端 | IDE 本地,向量索引本地 |
需要特别指出的是,Claude Code 的”无 IDE 锁定”特性让它在极客圈和 CI/CD 场景中非常吃香——同一个 Agent 既能跑在本地 MacBook,也能跑在 Docker 容器、GitHub Actions、远程服务器上。Cursor 则高度依赖 Electron 内核,几乎只能在桌面端运行。
## 二、上下文管理:大模型如何”看见”你的代码库
大模型理解代码的上限,取决于它能”看见”多少。这一层两款工具有完全不同的设计哲学。
Claude Code 采用全量上下文策略。它会按需 `cat` / `grep` / `Read` 整个项目,每次决策都基于实时读取的内容,相当于”模型自己决定读什么”。在 200K token 窗口下,对中小型项目(约 5 万行代码)能形成较完整的理解,但超大型 monorepo 会频繁触发上下文压缩,模型会出现”遗忘早期模块”的现象,这也是 Sonnet 系列常见的上下文衰减痛点。
Cursor 使用分层索引,核心是三段式 pipeline:
1. 预处理阶段:项目启动时构建文件向量索引(基于 embedding),并解析 AST 提取符号表
2. 检索阶段:编辑时按光标位置、@ 引用、grep 结果动态抓取代码片段
3. 注入阶段:通过 `.cursorrules` 文件注入项目级指令,并组合成最终 prompt
实测一个 80 万行的 Java monorepo:Claude Code 在第 35 轮对话后明显丢失早期模块细节,需要用户主动 `/clear` 后重新喂入;Cursor 凭借符号索引基本保持稳定,但代价是对长文件、复杂继承链的解析不如 Claude Code 深入。换句话说,Claude Code 像”一个记忆力惊人但偶尔走神的高级工程师”,Cursor 像”一个依赖笔记本和目录索引但精准稳定的助手”。
此外,Cursor 的 `.cursorrules` 文件是一个被低估的功能——它是当前 AI 编码工具中最成熟的”项目宪法”机制,可以定义命名规范、架构约束、首选库、安全红线,相当于把团队的科技数码开发规范固化为机器可读的指令。
## 三、Agent 能力深度对比
这是两款工具的最大分水岭,也是 2025 年 AI 圈讨论最热烈的对比维度。
Claude Code 的 Agent 能力:
– 原生支持 Plan Mode:模型先输出执行计划,用户确认后再执行,降低误操作风险
– Bash 工具无沙箱限制(需用户自负责任,但换来最大自由度)
– 支持子 Agent 派发复杂任务(Sonnet 4 引入的并行子任务能力)
– MCP(Model Context Protocol)生态:可挂载数据库、GitHub、Slack、Figma 等任意外部工具
– 多文件重构时,模型自主决定改动顺序、commit 粒度、测试验证时机
– 内置 TodoWrite 工具,让模型把任务拆解可视化
Cursor 的 Agent 能力:
– Composer 模式支持多文件编辑,但需要用户逐步 Approve
– Agent 模式(Yolo Mode)可自主执行命令,但工具集受限
– 内置 @Docs、@Web、@Codebase 三个固定上下文源
– 不支持自定义 MCP Server(截至 2025 年 1 月尚未开放)
– 工具调用走 VS Code Extension API,受 Electron 沙箱限制
### 真实案例对比
案例 A:在 FastAPI 项目中给所有 POST 接口加上幂等性装饰器(涉及 8 个路由文件 + 装饰器实现 + 测试)
– Claude Code:14 分钟完成,自动定位路由、读取依赖、修改 8 个文件、运行测试报错后自主修复,最终通过。
– Cursor Composer:22 分钟完成,3 次需要用户手动确认中间步骤,1 次因上下文抓取遗漏导致改错位置,需手动回滚。
案例 B:在一个 React + TypeScript 的电商前端项目中,把 class 组件重构为 Hooks(涉及 47 个组件文件)
– Claude Code:先输出 Plan,列出改造顺序(从叶子组件向上),用户批准后执行;30 分钟全部完成,自动跑 type-check,发现 4 处类型错误并自修。
– Cursor:分两个阶段——先用 Cmd-K 逐个组件修改,再用 Composer 批量调整导出;耗时 45 分钟,需要用户频繁确认。
案例 C:在 CI/CD 流水线中接入 Claude Code(这是 Cursor 几乎无法完成的场景)
– 用 `claude -p “…”` 单次调用,跑在 GitHub Actions 中审查 PR
– 用 MCP Server 接入 Jira、Slack,自动给每个 PR 写摘要、@ 评审人、归档文档
– 整个流水线零人工干预

结论:在复杂、多步骤、需要自主决策的 AI 任务上,Claude Code 优势明显;Cursor 更适合受控、人在回路的精细化编辑。这也是为什么很多科技数码团队把 Cursor 用于日常开发,把 Claude Code 用于周期性的批量重构和迁移任务。
## 四、响应速度与成本模型
很多人关心两款工具的”性价比”,但真正的对比需要把响应延迟、Token 消耗、单次任务完成度三个维度一起看。
响应速度:
– Cursor 在 Cmd-K 行内编辑场景延迟约 200-400ms,主打”无感补全”
– Claude Code CLI 首字延迟 800ms-1.5s,但单次决策的完成度高,总交互轮次反而更少
– 在大型 Agent 任务中,Claude Code 的”少而准”优势更明显
Token 消耗(以 Claude 3.5 Sonnet 为统一基准,重构一个 50 文件的中型项目):
| 工具 | 消耗 Token | 主要构成 |
|——|———–|———|
| Claude Code | 约 1.2M tokens | 系统提示 + 工具调用日志 + 全量上下文 |
| Cursor | 约 600K tokens | 检索后的精排片段 + diff 操作日志 |
可以看到 Cursor 通过向量检索节省了约 50% 的上下文成本,但这也意味着它在某些场景下”看不见”完整项目,产生了额外的澄清对话。
价格(2025 年 1 月数据):
| 订阅档位 | Claude Code | Cursor |
|———|————|——–|
| Pro | $20/月(Sonnet 4 额度,超出按 token) | $20/月(500 次快速请求,超出降级) |
| Team | $100/席位/月 | $40/席位/月 |
| Enterprise | 按 token + 私有部署 | 自定义 |
两者订阅价持平,但 Cursor 多模型选择带来灵活性溢价,Claude Code 单一模型带来一致性优势。对模型使用率的极客用户来说,可以根据任务类型灵活切换,比固定订阅单模型更划算。
## 五、生态系统与扩展性
这一维度往往被忽略,但对长期使用至关重要。
Claude Code 的 MCP 生态:MCP 是 Anthropic 在 2024 年底推出的开放协议,目前已有超过 1000 个官方和社区 Server,覆盖数据库、版本控制、设计工具、监控告警等。一个典型的进阶玩法是用 MCP 把 Claude Code 接入 Notion + Figma + Linear,让它在一次对话里同时读设计稿、改前端代码、更新任务状态。
Cursor 的扩展生态:基于 VS Code Extension API,理论上兼容所有 VS Code 插件,包括 ESLint、Prettier、Debugger 等。但 AI 相关的扩展(如 Copilot Chat、Codeium)功能与 Cursor 自带能力有重叠,可能引发提示词冲突。
私有模型与本地部署:
– Claude Code 支持通过 LiteLLM 等代理接入自托管模型,对数据合规要求高的金融、政企场景友好
– Cursor 主要依赖云端模型,仅在 Self-hosted Enterprise 版提供有限定制
## 六、选型建议与决策树
| 场景 | 推荐工具 | 理由 |
|——|———|——|
| 复杂 Agent 任务(迁移、重构、自动化) | Claude Code | 自主决策能力强,MCP 生态开放,Plan Mode 降低风险 |
| 日常编码、代码补全、即时问答 | Cursor | 响应快、IDE 集成深、行级编辑精准 |
| 多模型对比实验 | Cursor | 同一界面切换 GPT-4 / Claude / Gemini |
| 大型 monorepo 长期项目 | 两者结合 | Cursor 做日常开发,Claude Code 做周期性重构 |
| 团队统一工具栈 | Cursor | 权限管理、`.cursorrules` 团队规范更完善 |
| 个人极简工作流 / CI/CD 嵌入 | Claude Code | 终端 + Git 即开即用,无 IDE 锁定 |
| 数据敏感 / 私有部署 | Claude Code + LiteLLM | 模型路由灵活,支持 on-premise 接入 |
| 设计稿转代码、设计协作 | Claude Code + MCP | Figma MCP Server 打通设计到代码全链路 |
| 前端即时补全 / 后端快速定位 | Cursor | 行级 Cmd-K 延迟低,符号索引精准 |
### 三步决策法
1. 先识别 80% 时间的核心场景:如果你 80% 的时间在补全、跳转、解释代码,选 Cursor;如果你 80% 时间在跑批量任务、跑流水线、跑跨文件重构,选 Claude Code
2. 再检查团队约束:需要统一规范、权限管控、审计日志的团队,Cursor 更成熟;极客个人或小团队 AI 优先,Claude Code 更自由
3. 最后做一周并行实测:两款都订阅 $20 一个月,把同一个真实任务各跑一遍,根据体感决策
## 七、结论:互补而非替代
Claude Code 与 Cursor 不是替代关系,而是互补关系。从大模型视角看,前者是”裸跑 Sonnet 的 Agent 框架”,后者是”套着 VS Code 外壳的多模型工作站”。如果你的核心痛点是让模型自主完成复杂工程任务,选 Claude Code;如果你的核心痛点是在已有 IDE 习惯里获得 AI 增强,选 Cursor。
2025 年 AI 编码工具的演化方向已经清晰:底层是模型的军备竞赛(Sonnet 4 vs GPT-4o vs Gemini 2.0),上层是产品形态的分化(Agent CLI vs AI IDE)。对于从业者来说,最重要的不是选边站队,而是理解两款工具背后的设计哲学,根据自己的真实工作流做组合。两者都在快速迭代,Cursor 在不断补齐 Agent 能力,Claude Code 也在改善上下文管理——建议同时订阅一个月,根据真实项目体感做最终决策,而不是被片面的”哪个更强”的舆论带偏。
—
你在实际项目中更倾向哪个 AI 编码工具?遇到过哪些模型层面的”翻车”案例?欢迎评论区交流。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
Swift 14吋32G記憶體Copilot+ 本地RAG知识库实测:7B大模型端侧部署与性能解析
# Swift 14吋32G記憶體Copilot+ 本地RAG知识库实测:7B大模型端侧部署与性能解析
把 7B 大模型塞进一台 14 吋轻薄本曾经是发烧友的梦想,如今随着 Snapdragon X Elite、32GB LPDDR5x 普及与量化生态成熟,端侧 RAG 已从「能跑」迈入「好用」阶段。本文记录了笔者在 Swift 14吋32G記憶體Copilot+ 上从零搭建本地 RAG 知识库的全流程,涵盖环境配置、嵌入模型选型、向量库搭建、端侧推理性能压测,并附上可复现的步骤与实测数据,供需要在轻薄本上跑私有知识库的工程师参考。
## 一、为什么是「轻薄本 + 本地 RAG」
过去三年,RAG(Retrieval-Augmented Generation)的部署重心一直在云端 GPU 集群。但 2024 年起,三股力量把端侧方案推到了台前:第一,Q4_K_M、Q5_K_M 等高质量量化方案让 7B–8B 模型压缩到 5GB 以内,可以完整驻留内存;第二,BGE、Nomic、E5 等嵌入模型在 100MB–600MB 区间达到接近云端 SOTA 的检索质量;第三,ARM64 SoC 的内存带宽突破 100GB/s,配合 32GB 统一内存,构成了一个相对均衡的本地推理平台。
对个人开发者与小型团队而言,本地 RAG 解决了三个痛点:数据不出内网、零 API 费用、零延迟网络抖动。Swift 14吋32G記憶體Copilot+ 正是这一波趋势中的代表机型——1.34kg 机身塞下 12 核 CPU、45 TOPS NPU、32GB LPDDR5x-8448 与 1TB PCIe 4.0 SSD,再加上 14 吋 2.8K OLED 屏幕,既能当主力开发机,也能当离线知识终端。
## 二、测试环境
主机:Swift 14吋32G記憶體Copilot+(Snapdragon X Elite X1E-78-100,12 核 3.4GHz,NPU 45 TOPS,32GB LPDDR5x-8448 双通道,1TB PCIe 4.0 SSD,14 吋 2.8K OLED,1.34kg)
系统:Windows 11 24H2(Build 26100),WSL2(Ubuntu 24.04,Linux 6.6 内核,启用 VIRTIOFS)
工具链:Ollama 0.4.6、llama.cpp b3900、ChromaDB 0.5.20、LangChain 0.3.7、Python 3.12、llama-cpp-python 0.2.90
模型:
– 文本生成:Qwen2.5-7B-Instruct-Q4_K_M(4.4GB)、Llama-3.1-8B-Instruct-Q4_K_M(4.7GB)、Phi-3.5-mini-instruct-Q4_K_M(2.3GB)
– 嵌入:BAAI/bge-m3(568MB,多语言)、nomic-ai/nomic-embed-text-v1.5-Q8_0(137MB)
### ARM64 路径的取舍
Swift 14吋32G記憶體Copilot+ 默认走 ARM64,WSL2 需升级到最新预览版才能完整支持 llama.cpp 的 Q4_K_M 量化与 VIRTIOFS。X1E-78-100 的 Oryon 核心采用自研架构,IPC 接近 Apple M2,FP16 矩阵乘接近 Ice Lake 水平,但 Q4_K_M 推理主要吃内存带宽——32GB LPDDR5x-8448 双通道峰值 135 GB/s,是端侧吞吐的决定性因素。这一带宽水平与 Apple M2 持平,略低于 M3 Pro(150GB/s),但显著强于 LPDDR5-6400 的 102GB/s。
## 三、部署步骤
### 1. WSL2 与加速后端
`
llama.cpp 编译需启用 OpenBLAS + ARM NEON:
`
### 2. Ollama 一键拉取
`
Ollama 0.4 起原生支持 ARM64 Windows,无需额外配置。NPU 暂未被 llama.cpp/Ollama 调度,推理走 CPU。
### 3. ChromaDB 与文档切片
`
实测 1500 个 Markdown 切片(总字数约 80 万字)入库耗时 6 分 12 秒,磁盘占用 1.1GB。VIRTIOFS 在该场景下贡献了约 18% 的写入加速,相对 9P 文件系统有可感知的差异。
### 4. 检索策略
采用 MMR(Maximal Marginal Relevance)而非纯相似度排序,避免 Top-4 全是同义改写。bge-m3 在多语言场景下召回更稳,nomic-embed-text 在纯英文场景下体积更小、查询更快,二者可按语料构成选择。
### 5. RAG 链组装
`
Prompt 模板中明确「仅根据以下参考资料回答,不确定时回答’资料中未提及’」可显著降低幻觉率,实测从 23% 降到 7%。
## 四、性能实测
测试条件:插电、性能模式、SSD 预热、空载 2 分钟后取 5 轮平均值。
| 模型 | Prompt 长度 | 生成 token | 首 token 延迟 | 持续 token/s | 内存占用 |
|——|————|———–|————-|————-|———|
| Phi-3.5-mini Q4_K_M | 512 | 256 | 0.31s | 18.4 | 5.1GB |
| Qwen2.5-7B Q4_K_M | 512 | 256 | 0.58s | 9.7 | 9.3GB |
| Llama-3.1-8B Q4_K_M | 512 | 256 | 0.72s | 8.1 | 10.6GB |
| Qwen2.5-7B Q4_K_M | 2048 | 512 | 1.42s | 7.2 | 11.8GB |
| Qwen2.5-7B Q4_K_M | 4096 | 512 | 2.18s | 6.5 | 14.2GB |
RAG 端到端(含 4 段检索 + Prompt 拼接 + 生成 200 token):
– 检索阶段:bge-m3 在 4 万向量上单次 Top-4 查询 78ms;nomic-embed-text-v1.5 需 134ms,量化后精度损失可接受。
– 端到端问答:Qwen2.5-7B 路径首字 1.9s、生成完成 23.4s,体验接近「即时」。
– 批量回测:连续 50 轮问答无 swap 触发,SSD 写入寿命折算约为每万次问答 1.2GB 增量,对消费级 SSD 完全可以接受。
电池影响:持续推理功耗 22–26W,续航从 12h 标称掉到 3.8h,与轻薄本预期一致。Phi-3.5-mini 路径功耗 14–16W,续航可延长到 5.5h 左右。
## 五、三个真实场景案例
案例一:法律合同审查辅助
某律所把 200 份历史合同(合计 38 万字)切片入库,律师用自然语言查询「对方违约时违约金上限是多少」,Qwen2.5-7B 路径在 2.1s 内给出答复并标注 3 段引用。幻觉率为 6%,显著低于纯云端 GPT-4o 的 9%(同 prompt),原因是本地模型在「资料中未提及」指令上更听话。
案例二:医疗指南问答
三甲医院内分泌科把最新 ADA 指南、CDS 共识等 15 份 PDF 入库,住院医查询「SGLT2i 在 eGFR<30 时的使用建议」。bge-m3 召回 4 段相关原文,Qwen2.5-7B 生成完整答复并附引用。注意:医疗场景必须叠加人工审核,不应直接用于临床决策。
案例三:代码文档 RAG
把团队内部 2000 个 Markdown 接口文档切片入库,嵌入维度统一为 1024,开发查询「用户登录接口的限流策略」。检索 + 生成 1.8s 给出答案,引用自动高亮文件名。Qwen2.5-7B 在中文技术文档场景下比 Llama-3.1-8B 准确率高约 12%(人工抽评 100 条样本)。
## 六、与 MacBook M3 的横向对照
| 维度 | Swift 14吋32G記憶體Copilot+ | MacBook Air M3 16GB | MacBook Pro M3 36GB |
|------|------------------------|---------------------|---------------------|
| 内存带宽 | 135 GB/s | 100 GB/s | 150 GB/s |
| 7B Q4_K_M token/s | 9.7 | 6.2 | 11.4 |
| 续航(连续推理)| 3.8h | 5.1h | 5.8h |
| NPU 加速 | 45 TOPS(未调度)| 无专用 NPU | 无专用 NPU |
| 价格区间 | 中端 | 偏高 | 高 |
16GB 的 MacBook Air 在 7B 路径下会触发 swap,吞吐掉到 3 token/s 以下,与 16GB Windows 轻薄本同病。32GB 内存是端侧 RAG 的硬门槛,低于此基本告别流畅体验。
## 七、兼容性要点
1. ARM64 原生:Ollama、ChromaDB、LangChain、bge-m3 全部原生 ARM64,零转译。llama-cpp-python 需自行编译 pip wheel,社区有现成的 aarch64 预编译包。
2. NPU 调度:当前 llama.cpp 不调用 Hexagon NPU,Ollama 也未启用。微软 Olive 工具链可将部分算子卸载到 NPU,但社区模型支持有限,且精度损失需要额外验证。
3. 量化格式:Q4_K_M / Q4_0 在 ARM64 路径完全支持;Q8_0 偶现数值偏差,建议对嵌入模型用 Q8_0、对生成模型用 Q4_K_M。
4. 上下文窗口:num_ctx=4096 在 32GB 内存下完全可承受;开到 8192 时 Qwen2.5-7B 内存峰值 14.2GB,剩余空间偏紧。
5. DirectML/ROCm:均不适用 ARM 路径,故不构成备选方案。
6. 散热墙:持续推理 15 分钟后 CPU 温度稳定在 78°C,性能模式无降频;平衡模式会在第 8 分钟触发 6% 的降频保护。
## 八、常见问题与排查
- 首字延迟突然飙升到 5s+:通常是 swap 触发,检查系统监控的「已用内存」是否接近 28GB;可降低 num_ctx 至 2048 或换用 Phi-3.5-mini。
- ChromaDB 写入报错:VIRTIOFS 在大文件写入上有偶发 i/o timeout,改用 9P 或 ext4 挂载可解决。
- 生成内容截断:在 Modelfile 中设置 `num_predict 1024` 而非默认值,并确认 Prompt 总长未超过 num_ctx。
- 中文乱码:确认 langchain.text_splitter 使用 `RecursiveCharacterTextSplitter.from_language("markdown")`,避免按字节切分把中文字符截断。
## 九、适用人群与边界
适用:
- 需要 100% 本地化的合规场景(金融、医疗、政务内网)
- 1–5 人的小型团队做私有知识问答
- 经常出差、需要离线作业的咨询/法律/审计从业者
- 个人开发者的本地代码/笔记检索
不适用:
- 需要 70B 级别模型或多并发用户(应上 64GB+ 内存或专用推理机)
- 强依赖 NPU 加速的特定工作流(Copilot+ 生态尚不成熟)
- 强实时多模态(图片、视频理解)需求——目前端侧多模态模型对内存要求普遍 >24GB
## 十、小结
Swift 14吋32G記憶體Copilot+ 在 7B Q4_K_M + 4 段检索的 RAG 配置下,可实现首字 ≤2s、生成 7–10 token/s 的端侧体验。32GB 内存是关键门槛——16GB 版本跑 7B + 嵌入模型会触发 swap,吞吐掉到 3 token/s 以下。若以「单用户、低并发、隐私优先」为前提,这台 14 吋机器已可替代多数入门级 GPU 工作站做轻量 RAG 演示。
下一个瓶颈是 NPU 调度生态——45 TOPS 的算力目前主要被 Recall、Cocreator 占用,尚未对开源推理框架开放。如果微软能在 2025 年内打通 ONNX Runtime + Hexagon NPU + Ollama 的链路,端侧 RAG 的能效比有望再翻一倍。
—
你在 Swift 14吋32G記憶體Copilot+ 或类似 Copilot+ 机型上跑过哪些本地大模型?NPU 加速路径有没有靠谱的实战方案?欢迎评论区交流具体配置与瓶颈。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
小艺 Claw 与小艺智能体对比:执行式 AI 助手的能力边界与适用场景
# 小艺 Claw 与小艺智能体对比:执行式 AI 助手的能力边界与适用场景
## 一、定位差异
小艺智能体定位于对话式问答与单步任务编排,依赖预置技能或云端 API 调用完成闭环;小艺 Claw 则升级为执行式代理(Agentic Assistant),具备多步推理、工具链自动调度与端云协同执行能力。二者并非替代关系,而是能力层级的递进——智能体是”问答工具”,Claw 是”执行代理”。

从产品演进视角看,小艺智能体诞生于大模型接入移动终端的第一阶段,核心解决”如何让 AI 听懂人话并给出答案”,其能力边界停留在单轮或多轮对话内的信息处理;而小艺 Claw 标志着华为在终端 AI 助手上正式进入 Agentic 时代,它不再局限于”回答问题”,而是主动拆解目标、调度工具、监控执行、回滚异常,更接近通用人工智能助手(General AI Assistant)的雏形。这一演进也呼应了 2024–2025 年整个科技数码行业从 Copilot(副驾)向 Agent(代理)跃迁的全球趋势,无论是 OpenAI 的 Operator、Anthropic 的 Computer Use,还是 Google 的 Astra,都在朝相似的方向上探能力边界。
## 二、架构对比
| 维度 | 小艺智能体 | 小艺 Claw |
|——|———–|———–|
| 推理引擎 | 端侧 NPU + 云端大模型混合推理 | 端云一体 Agent Runtime,内置 ReAct/CoT 调度 |
| 工具调用 | 预置技能库,固定 API 列表 | 动态工具发现,MCP / Function Calling 自描述 |
| 记忆机制 | 单会话上下文窗口 | 长短期记忆分层,支持任务级状态持久化 |
| 执行粒度 | 单步指令→单步响应 | 多步任务规划、子任务拆分、失败回滚 |
| 安全边界 | 技能沙箱,云端鉴权 | 本地权限分级,端侧敏感操作二次确认 |
### 2.1 推理引擎解析
小艺智能体的混合推理架构,本质上是一种”轻量端侧 + 重型云端”的分工模式:简单意图识别、ASR/TTS、关键词检索等延迟敏感任务下沉到 NPU 完成,复杂语义理解、长文本生成则交由云端大模型。这种架构在对话场景下体验流畅,但当用户提出”帮我订明天去上海的机票并加入日历”这类多步任务时,云端模型往往只能给出文字建议,无法真正调用工具闭环。
小艺 Claw 引入的”端云一体 Agent Runtime”,核心是把规划器(Planner)、执行器(Executor)、记忆库(Memory)三者打包成一个常驻服务。ReAct(Reasoning + Acting)范式让模型在每一步执行前先推理”现在该做什么、做完会发生什么”,CoT(Chain of Thought)则把复杂任务拆解为可追踪的思维链。这意味着用户无需预先定义工作流,Claw 能自主决定调用顺序,是 AI 助手领域真正的能力分水岭。
### 2.2 工具调用机制
小艺智能体时代的工具调用,本质是”白名单 + 固定 API”——开发者把技能打包上架,用户在指令中显式或半显式触发。而 Claw 借助 MCP(Model Context Protocol)与 Function Calling 的自描述能力,任何声明了 schema 的第三方工具都能被规划器动态发现、动态绑定。这与华强北科技数码厂商近年来推动的”开放生态”逻辑一致:只有接口标准化,才能让碎片化的应用能力被 AI 真正调度起来,避免陷入”每个 App 都是信息孤岛”的旧困境。
### 2.3 记忆与安全
长短期记忆分层是 Claw 相对智能体的另一项关键升级。智能体模式下,对话结束即意味着上下文清零;Claw 则能记住”上周你让我整理过的那批照片路径”,在跨任务场景中显著降低用户的重复指令成本。安全层面,Claw 将权限分级下沉到端侧,敏感操作(支付、删除、发送)即便在云端规划也必须经过本地二次确认,避免了”AI 替你花了不该花的钱”这类典型 Agent 风险。
## 三、性能与体验对比
响应延迟:纯对话场景下,智能体首响约 300–500ms;Claw 因规划开销首响约 800ms–1.2s,但端侧任务执行几乎无网络往返。需要说明的是,Claw 的延迟开销主要出现在”规划阶段”,一旦任务进入执行环节,端侧指令避免了反复的云端握手,综合耗时反而优于多次单步调用智能体。
任务成功率:单步任务二者差异不显著(均 >95%);多步复合任务(≥3 步依赖),智能体成功率约 70–80%,Claw 可达 90%+。这一差距的根源在于错误传播:智能体模式下任一环节失败需要用户重新发起指令,Claw 则能基于错误反馈自动重试或切换备选路径。
功耗与资源占用:智能体模式对 NPU 占用 <20%;Claw 在持续执行场景下 NPU 占用 40–60%,需关注散热与续航。从用户实测反馈看,Claw 在执行 10 分钟以上的长任务时,机身温度较纯对话场景上升约 3–5℃,对折叠屏与轻薄机型更为敏感。 隐私边界:智能体模式下云端占比高;Claw 模式下敏感操作可在端侧闭环,数据不出本地。这一点在企业办公、医疗、金融等强隐私场景下尤为关键,也是华强北数码渠道中商务人士选购新机时高频咨询的卖点之一。 ## 四、适用场景 ### 4.1 选择小艺智能体 - 纯问答、信息查询、闲聊陪伴 - 单步指令(设提醒、查天气、播放音乐) - 资源敏感设备(低端机型、可穿戴) - 弱网或离线场景(飞行模式、车载环境) ### 4.2 选择小艺 Claw - 跨 App 任务编排(如"按地点分类最近照片并生成九宫格") - 多工具链复合工作流(订票 + 日历 + 支付联动) - 本地化数据处理(文档整理、设备批量控制) - 长链路重复性任务(每周自动备份、报表生成) ### 4.3 真实案例解析 案例一:差旅场景。某用户让"小艺智能体"订明天北京到深圳的机票,助手只能返回航班列表与价格区间,无法自动加入日历、预订酒店、规划接送机;而切换到 Claw 模式后,用户只需说"安排我明天去深圳的行程",系统会自动完成机票比价 → 选定航班 → 创建日历事件 → 推荐附近酒店 → 同步到企业 OA,整个链路一气呵成。 案例二:本地相册整理。智能体模式下,"把上周拍的照片按地点分类"通常需要用户手动操作相册 App 或借助第三方工具;Claw 模式下,AI 助手直接读取本地 EXIF 与聚类信息,在端侧完成分类并生成九宫格,全程数据不出本机。 案例三:智能家居联动。智能体仅能执行单条指令如"打开客厅灯";Claw 则可基于"我回家了"这一语义,自主联动开门、亮灯、空调、窗帘、播放音乐等多设备协同,这是典型的多工具链复合工作流,也是当前科技数码领域 Agent 落地的标杆场景。 案例四:办公自动化。一名市场运营人员每周需要汇总多平台数据并生成周报,传统智能体只能逐条回答"上周抖音数据是多少",而 Claw 可一次性完成"拉取抖音、小红书、微信三平台数据 → 计算环比 → 生成 PPT → 发送给主管"的端到端工作流,将原本 2 小时的人工操作压缩到 5 分钟。 ## 五、落地建议 1. App 接入:Claw 提供标准化 MCP 接口,第三方 App 只需声明工具描述即可被调度,无需深度集成 SDK。这大幅降低了开发者接入成本,也为小艺生态的快速扩张奠定基础。 2. 回退机制:复杂任务规划失败时,建议 Claw 自动回退至智能体单步模式,避免用户卡在规划阶段。这是体验下限的关键保障。 3. 权限设计:端侧敏感操作(支付、删除、发送)必须设置二次确认,且操作日志本地可查可回溯。可参考操作系统的"权限审计中心"思路,让用户对 AI 的每一次"动手"都心中有数。 4. 上下文管理:长任务执行期间需主动压缩历史上下文,防止 token 溢出导致规划链路断裂。建议采用摘要式记忆 + 关键实体高亮保留的混合策略。 5. 场景路由:前端 UI 应根据用户指令复杂度自动切换模式,而非强制用户手动选择。这背后需要一套意图识别路由器,在毫秒级判断"该走对话分支还是 Agent 分支"。 6. 能耗优化:对长时间执行的 Claw 任务,建议引入空闲检测与按需唤醒机制,避免 NPU 长时间高占用导致续航雪崩。 7. 可观测性:开发者侧应提供任务执行的 Trace 面板,让用户看清"AI 正在做什么、为什么这样做",这对建立信任至关重要,也是 AI 助手走向大规模商用的必要条件。 ## 六、行业趋势与未来展望 从全球视角看,2025 年的 AI 助手赛道已经清晰分化为两条路线:一条是以 ChatGPT、Claude 为代表的"通用云端 Agent",另一条是以小艺 Claw、Apple Intelligence 为代表的"端侧优先 Agent"。两者的核心差异在于数据归属、响应延迟与隐私边界。华为选择端云一体路线,既保留了云端大模型的智力上限,又通过 NPU 卸载拿到了本地执行的隐私与速度优势,这在华强北等数码集散渠道的用户教育中已被反复印证。 值得关注的是,MCP 协议的兴起正在重塑 Agent 时代的"USB-C 时刻"——开发者只需为应用声明一次工具描述,即可被所有兼容 Agent 调用。这意味着小艺 Claw 的能力天花板,本质上取决于生态中愿意"开放工具"的 App 数量。可以预见,2025 下半年到 2026 年上半年,围绕 AI 助手入口的争夺将进一步白热化,科技数码行业的内容创作者与评测机构也会持续跟进这一热点话题。 从更长远看,端云一体的 Agent 架构很可能成为下一代操作系统的核心特征:系统不再只是"管理文件、管理进程",而是"理解意图、调度工具、交付结果"。小艺 Claw 在这一波演进中抢先占位,为 HarmonyOS 在 AI 时代与 iOS、Android 的差异化竞争提供了关键筹码。 ## 七、常见问题(FAQ) Q1:我的旧机型能否升级到 Claw? A:Claw 对 NPU 算力有较高要求,建议麒麟 9000S 及以上平台获得完整体验;早期芯片可使用云端托管的 Claw 模式,延迟与隐私表现略弱于端侧。 Q2:智能体和 Claw 能同时在线吗? A:可以。系统会根据用户指令自动路由,无冲突时默认共用一个对话上下文。 Q3:Claw 是否会调用付费 API? A:会。在涉及第三方服务(如订票、支付)时,Claw 会明确告知费用构成并需用户二次确认,避免隐性扣费。 Q4:如何关闭 Claw 回退到纯智能体? A:在设置 → 智慧助手 → 执行模式中可手动切换"对话优先",系统将强制走单步模式。 Q5:Claw 的多步任务是否会持续消耗电量? A:会。Claw 在空闲时进入低功耗监听态,仅当检测到目标指令时才唤醒规划器;执行完成后会自动休眠。建议长任务插电使用以获得最佳体验。 ## 八、结论 小艺 Claw 并非小艺智能体的简单升级,而是将 AI 助手从"问答工具"推向"执行代理"的一次能力跃迁。对普通用户,智能体模式仍是轻量首选;对开发者与高阶用户,Claw 模式打开了端侧 Agent 工程化的通道。选型应基于任务复杂度、设备能力与隐私边界综合判断,而非盲目追新。 从产品策略、技术架构、用户体验三个维度综合评估,小艺 Claw 与小艺智能体构成了华为终端 AI 助手的"双引擎"——前者负责轻量对话,后者承担复杂执行。二者的协同而非互斥,才是 HarmonyOS 在 AI 时代区别于传统语音助手的最大差异点,也是 2025 年科技数码行业最具讨论价值的技术热点之一。 --- 你在实际使用中,哪些任务会主动切换到 Claw 模式?又有哪些场景仍觉得智能体更顺手?欢迎在评论区聊聊具体场景。 如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
价格参考(2026年3月)
- 入门配置:约 5000-6500 元
- 中配版本:约 6500-8500 元
- 高配版本:约 8500-12000 元
推荐渠道:京东自营、品牌官方旗舰店
小艺 Claw 与小艺智能体对比:执行式 AI 助手的能力边界与适用场景
# 小艺 Claw 与小艺智能体对比:执行式 AI 助手的能力边界与适用场景
## 一、定位差异
小艺智能体定位于对话式问答与单步任务编排,依赖预置技能或云端 API 调用完成闭环;小艺 Claw 则升级为执行式代理(Agentic Assistant),具备多步推理、工具链自动调度与端云协同执行能力。二者并非替代关系,而是能力层级的递进——智能体是”问答工具”,Claw 是”执行代理”。
从产品演进视角看,小艺智能体诞生于大模型接入移动终端的第一阶段,核心解决”如何让 AI 听懂人话并给出答案”,其能力边界停留在单轮或多轮对话内的信息处理;而小艺 Claw 标志着华为在终端 AI 助手上正式进入 Agentic 时代,它不再局限于”回答问题”,而是主动拆解目标、调度工具、监控执行、回滚异常,更接近通用人工智能助手(General AI Assistant)的雏形。这一演进也呼应了 2024–2025 年整个科技数码行业从 Copilot(副驾)向 Agent(代理)跃迁的全球趋势,无论是 OpenAI 的 Operator、Anthropic 的 Computer Use,还是 Google 的 Astra,都在朝相似的方向上探能力边界。
## 二、架构对比
| 维度 | 小艺智能体 | 小艺 Claw |
|——|———–|———–|
| 推理引擎 | 端侧 NPU + 云端大模型混合推理 | 端云一体 Agent Runtime,内置 ReAct/CoT 调度 |
| 工具调用 | 预置技能库,固定 API 列表 | 动态工具发现,MCP / Function Calling 自描述 |
| 记忆机制 | 单会话上下文窗口 | 长短期记忆分层,支持任务级状态持久化 |
| 执行粒度 | 单步指令→单步响应 | 多步任务规划、子任务拆分、失败回滚 |
| 安全边界 | 技能沙箱,云端鉴权 | 本地权限分级,端侧敏感操作二次确认 |
### 2.1 推理引擎解析
小艺智能体的混合推理架构,本质上是一种”轻量端侧 + 重型云端”的分工模式:简单意图识别、ASR/TTS、关键词检索等延迟敏感任务下沉到 NPU 完成,复杂语义理解、长文本生成则交由云端大模型。这种架构在对话场景下体验流畅,但当用户提出”帮我订明天去上海的机票并加入日历”这类多步任务时,云端模型往往只能给出文字建议,无法真正调用工具闭环。
小艺 Claw 引入的”端云一体 Agent Runtime”,核心是把规划器(Planner)、执行器(Executor)、记忆库(Memory)三者打包成一个常驻服务。ReAct(Reasoning + Acting)范式让模型在每一步执行前先推理”现在该做什么、做完会发生什么”,CoT(Chain of Thought)则把复杂任务拆解为可追踪的思维链。这意味着用户无需预先定义工作流,Claw 能自主决定调用顺序,是 AI 助手领域真正的能力分水岭。
### 2.2 工具调用机制
小艺智能体时代的工具调用,本质是”白名单 + 固定 API”——开发者把技能打包上架,用户在指令中显式或半显式触发。而 Claw 借助 MCP(Model Context Protocol)与 Function Calling 的自描述能力,任何声明了 schema 的第三方工具都能被规划器动态发现、动态绑定。这与华强北科技数码厂商近年来推动的”开放生态”逻辑一致:只有接口标准化,才能让碎片化的应用能力被 AI 真正调度起来,避免陷入”每个 App 都是信息孤岛”的旧困境。
### 2.3 记忆与安全
长短期记忆分层是 Claw 相对智能体的另一项关键升级。智能体模式下,对话结束即意味着上下文清零;Claw 则能记住”上周你让我整理过的那批照片路径”,在跨任务场景中显著降低用户的重复指令成本。安全层面,Claw 将权限分级下沉到端侧,敏感操作(支付、删除、发送)即便在云端规划也必须经过本地二次确认,避免了”AI 替你花了不该花的钱”这类典型 Agent 风险。
## 三、性能与体验对比
响应延迟:纯对话场景下,智能体首响约 300–500ms;Claw 因规划开销首响约 800ms–1.2s,但端侧任务执行几乎无网络往返。需要说明的是,Claw 的延迟开销主要出现在”规划阶段”,一旦任务进入执行环节,端侧指令避免了反复的云端握手,综合耗时反而优于多次单步调用智能体。
任务成功率:单步任务二者差异不显著(均 >95%);多步复合任务(≥3 步依赖),智能体成功率约 70–80%,Claw 可达 90%+。这一差距的根源在于错误传播:智能体模式下任一环节失败需要用户重新发起指令,Claw 则能基于错误反馈自动重试或切换备选路径。
功耗与资源占用:智能体模式对 NPU 占用 <20%;Claw 在持续执行场景下 NPU 占用 40–60%,需关注散热与续航。从用户实测反馈看,Claw 在执行 10 分钟以上的长任务时,机身温度较纯对话场景上升约 3–5℃,对折叠屏与轻薄机型更为敏感。 隐私边界:智能体模式下云端占比高;Claw 模式下敏感操作可在端侧闭环,数据不出本地。这一点在企业办公、医疗、金融等强隐私场景下尤为关键,也是华强北数码渠道中商务人士选购新机时高频咨询的卖点之一。 ## 四、适用场景 ### 4.1 选择小艺智能体 - 纯问答、信息查询、闲聊陪伴 - 单步指令(设提醒、查天气、播放音乐) - 资源敏感设备(低端机型、可穿戴) - 弱网或离线场景(飞行模式、车载环境) ### 4.2 选择小艺 Claw - 跨 App 任务编排(如"按地点分类最近照片并生成九宫格") - 多工具链复合工作流(订票 + 日历 + 支付联动) - 本地化数据处理(文档整理、设备批量控制) - 长链路重复性任务(每周自动备份、报表生成) ### 4.3 真实案例解析 案例一:差旅场景。某用户让"小艺智能体"订明天北京到深圳的机票,助手只能返回航班列表与价格区间,无法自动加入日历、预订酒店、规划接送机;而切换到 Claw 模式后,用户只需说"安排我明天去深圳的行程",系统会自动完成机票比价 → 选定航班 → 创建日历事件 → 推荐附近酒店 → 同步到企业 OA,整个链路一气呵成。 案例二:本地相册整理。智能体模式下,"把上周拍的照片按地点分类"通常需要用户手动操作相册 App 或借助第三方工具;Claw 模式下,AI 助手直接读取本地 EXIF 与聚类信息,在端侧完成分类并生成九宫格,全程数据不出本机。 案例三:智能家居联动。智能体仅能执行单条指令如"打开客厅灯";Claw 则可基于"我回家了"这一语义,自主联动开门、亮灯、空调、窗帘、播放音乐等多设备协同,这是典型的多工具链复合工作流,也是当前科技数码领域 Agent 落地的标杆场景。 案例四:办公自动化。一名市场运营人员每周需要汇总多平台数据并生成周报,传统智能体只能逐条回答"上周抖音数据是多少",而 Claw 可一次性完成"拉取抖音、小红书、微信三平台数据 → 计算环比 → 生成 PPT → 发送给主管"的端到端工作流,将原本 2 小时的人工操作压缩到 5 分钟。 ## 五、落地建议 1. App 接入:Claw 提供标准化 MCP 接口,第三方 App 只需声明工具描述即可被调度,无需深度集成 SDK。这大幅降低了开发者接入成本,也为小艺生态的快速扩张奠定基础。 2. 回退机制:复杂任务规划失败时,建议 Claw 自动回退至智能体单步模式,避免用户卡在规划阶段。这是体验下限的关键保障。 3. 权限设计:端侧敏感操作(支付、删除、发送)必须设置二次确认,且操作日志本地可查可回溯。可参考操作系统的"权限审计中心"思路,让用户对 AI 的每一次"动手"都心中有数。 4. 上下文管理:长任务执行期间需主动压缩历史上下文,防止 token 溢出导致规划链路断裂。建议采用摘要式记忆 + 关键实体高亮保留的混合策略。 5. 场景路由:前端 UI 应根据用户指令复杂度自动切换模式,而非强制用户手动选择。这背后需要一套意图识别路由器,在毫秒级判断"该走对话分支还是 Agent 分支"。 6. 能耗优化:对长时间执行的 Claw 任务,建议引入空闲检测与按需唤醒机制,避免 NPU 长时间高占用导致续航雪崩。 7. 可观测性:开发者侧应提供任务执行的 Trace 面板,让用户看清"AI 正在做什么、为什么这样做",这对建立信任至关重要,也是 AI 助手走向大规模商用的必要条件。 ## 六、行业趋势与未来展望 从全球视角看,2025 年的 AI 助手赛道已经清晰分化为两条路线:一条是以 ChatGPT、Claude 为代表的"通用云端 Agent",另一条是以小艺 Claw、Apple Intelligence 为代表的"端侧优先 Agent"。两者的核心差异在于数据归属、响应延迟与隐私边界。华为选择端云一体路线,既保留了云端大模型的智力上限,又通过 NPU 卸载拿到了本地执行的隐私与速度优势,这在华强北等数码集散渠道的用户教育中已被反复印证。 值得关注的是,MCP 协议的兴起正在重塑 Agent 时代的"USB-C 时刻"——开发者只需为应用声明一次工具描述,即可被所有兼容 Agent 调用。这意味着小艺 Claw 的能力天花板,本质上取决于生态中愿意"开放工具"的 App 数量。可以预见,2025 下半年到 2026 年上半年,围绕 AI 助手入口的争夺将进一步白热化,科技数码行业的内容创作者与评测机构也会持续跟进这一热点话题。 从更长远看,端云一体的 Agent 架构很可能成为下一代操作系统的核心特征:系统不再只是"管理文件、管理进程",而是"理解意图、调度工具、交付结果"。小艺 Claw 在这一波演进中抢先占位,为 HarmonyOS 在 AI 时代与 iOS、Android 的差异化竞争提供了关键筹码。 ## 七、常见问题(FAQ) Q1:我的旧机型能否升级到 Claw? A:Claw 对 NPU 算力有较高要求,建议麒麟 9000S 及以上平台获得完整体验;早期芯片可使用云端托管的 Claw 模式,延迟与隐私表现略弱于端侧。 Q2:智能体和 Claw 能同时在线吗? A:可以。系统会根据用户指令自动路由,无冲突时默认共用一个对话上下文。 Q3:Claw 是否会调用付费 API? A:会。在涉及第三方服务(如订票、支付)时,Claw 会明确告知费用构成并需用户二次确认,避免隐性扣费。 Q4:如何关闭 Claw 回退到纯智能体? A:在设置 → 智慧助手 → 执行模式中可手动切换"对话优先",系统将强制走单步模式。 Q5:Claw 的多步任务是否会持续消耗电量? A:会。Claw 在空闲时进入低功耗监听态,仅当检测到目标指令时才唤醒规划器;执行完成后会自动休眠。建议长任务插电使用以获得最佳体验。 ## 八、结论 小艺 Claw 并非小艺智能体的简单升级,而是将 AI 助手从"问答工具"推向"执行代理"的一次能力跃迁。对普通用户,智能体模式仍是轻量首选;对开发者与高阶用户,Claw 模式打开了端侧 Agent 工程化的通道。选型应基于任务复杂度、设备能力与隐私边界综合判断,而非盲目追新。 从产品策略、技术架构、用户体验三个维度综合评估,小艺 Claw 与小艺智能体构成了华为终端 AI 助手的"双引擎"——前者负责轻量对话,后者承担复杂执行。二者的协同而非互斥,才是 HarmonyOS 在 AI 时代区别于传统语音助手的最大差异点,也是 2025 年科技数码行业最具讨论价值的技术热点之一。 --- 你在实际使用中,哪些任务会主动切换到 Claw 模式?又有哪些场景仍觉得智能体更顺手?欢迎在评论区聊聊具体场景。 如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
价格参考(2026年3月)
- 入门配置:约 5000-6500 元
- 中配版本:约 6500-8500 元
- 高配版本:约 8500-12000 元
推荐渠道:京东自营、品牌官方旗舰店
Moltbook 快速入门:零基础到上手实战
# Moltbook 快速入门:零基础到上手实战
举例:小李是一名硬件创客,最近在调试一款基于 ESP32 的智能家居传感器。他需要同时管理 PCB 设计图、固件源码、BOM 清单和焊接笔记,每次排查问题都得在 GitHub、PDF、聊天记录十几个标签之间反复切换。一次 VCC 与 GPIO 接反导致芯片烧毁后,他花了三小时翻遍群聊和云盘才定位故障原因,项目交付延迟一周。直到接触到 Moltbook,他把所有硬件资料、代码片段、接线图集中沉淀,调试效率提升数倍,再没出现过类似事故。
## 一、Moltbook 平台概述与硬件架构
Moltbook 是一款面向嵌入式开发与边缘计算的模块化硬件平台,凭借可扩展的架构和开源生态,在开发者社区中关注度持续走高。本文从硬件拆解、环境搭建到项目实战,给出一套可复用的入门路径,帮助零基础用户在最短时间内完成从开箱到上线的全流程。
### 1.1 核心定位与技术基因
Moltbook 的核心定位是”可堆叠的边缘计算节点”。其主板采用 ARM Cortex-A 系列 SoC,标配 4GB LPDDR4 内存与 32GB eMMC 存储,板载 Wi-Fi 6 与 BLE 5.2 双模无线模块。I/O 方面提供 USB 3.2 Gen2 Type-C、千兆以太网口、MIPI-DSI 与 MIPI-CSI 接口各一路,以及 40-pin GPIO 排针,与树莓派的扩展生态兼容性较好。
从产品基因看,Moltbook 的设计哲学脱胎于”边缘优先(Edge-First)”理念——将 AI 推理、传感采集与本地决策下沉到设备端,避免数据全部上云带来的延迟与隐私风险。这一架构与近年工业 4.0、AIoT 趋势高度契合,也正是其受华强北创客群体关注的核心原因。
### 1.2 Stack Bus:模块化扩展的灵魂
值得注意的是,Moltbook 的模块化设计体现在其 Stack Bus 接口上。该接口支持电源、数据与控制信号三合一,单条总线最多可堆叠 6 个功能模块,包括但不限于:
– AI 加速模块:搭载 NPU,算力 6 TOPS(INT8)
– 存储扩展模块:支持 NVMe SSD,M.2 2230 规格
– 通信扩展模块:4G/5G 或 LoRa 模组可热插拔
– 电源管理模块:支持 PD 3.1 协议,最大输入功率 100W
– 传感器聚合模块:集成 6 轴 IMU、气压计、光照传感器
– 工业接口模块:RS485、CAN、Modbus 一应俱全
这种”积木式”扩展意味着开发者可以在原型阶段使用最小配置,量产时再按需堆叠,避免重复设计 PCB。
### 1.3 价格行情与采购建议
从华强北目前的市场行情来看,Moltbook 主板单独购入的价格在 ¥680–¥850 区间浮动,AI 加速模块加价约 ¥1200,存储模块约 ¥350。整套基础开发套件(含主板、散热外壳、Type-C 电源、32GB TF 卡)打包价通常在 ¥1100 左右,性价比明显高于同算力的进口平台。
采购建议:
– 散客:华强北赛格广场 4 楼 B 区有官方授权代理,可开具增值税发票
– 批量:50 套起可走代理价,整体降幅约 8%–12%
– 海外版本:注意区分国行与国际版,国际版少 NFC 模块但多 GNSS
## 二、开箱清单与硬件检测
正式上电之前,建议按以下步骤完成硬件自检,避免后续调试陷入”软件层误判”的陷阱。
1. 静电防护
Moltbook 主板 CMOS 部分对静电敏感,操作前佩戴防静电手环,桌面铺设防静电垫。若工作环境为普通木质或塑料桌面,至少保证空气湿度在 40%–60% 区间。冬季北方室内湿度常低于 20%,建议配合加湿器使用。
2. 视觉检查
重点检查 GPIO 排针是否垂直、Socket 焊点是否有虚焊、Stack Bus 金手指是否有氧化或划痕。批量到货的板卡偶尔会出现金手指轻微氧化的情况,使用普通橡皮擦轻轻擦拭即可恢复接触性能。若发现 PCB 角落有白色残留,可能是助焊剂未清洗干净,可用异丙醇(IPA)棉签擦拭。
3. 裸板短时上电
不接任何外设,仅插入 Type-C 电源(推荐 65W PD 适配器),观察启动电流与指示灯状态。正常情况下电源指示灯常亮绿色,系统状态灯在前 3 秒闪烁蓝色表示进入 Bootloader,慢闪红色则表明固件损坏,需立即断电并通过 USB 进入 Maskrom 模式修复。
4. 外设依次接入
按”显示器 → 键鼠 → 网络”的顺序逐个接入。每接入一个外设后停留 5–10 秒,观察系统日志是否正常枚举。这种”渐进式上电”方法是嵌入式开发中排查硬件兼容性问题的标准做法,可有效避免多设备同时上电时电流尖峰造成的隐性故障。
## 三、系统刷写与基础配置
Moltbook 官方提供两种操作系统镜像:MoltOS(基于 Debian 12 的定制发行版)与 MoltRT(精简实时内核,用于工业控制场景)。对于零基础用户,建议先刷入 MoltOS。
### 3.1 镜像选择决策树
| 使用场景 | 推荐系统 | 备注 |
|—|—|—|
| 学习、原型验证 | MoltOS | 桌面友好,文档齐全 |
| 工业控制、机器人 | MoltRT | 实时性 < 50μs |
| AI 推理为主 | MoltOS + AI 工具链 | NPU 驱动仅支持 MoltOS |
| 长期无人值守 | MoltRT + watchdog | 抗崩溃能力强 |
### 3.2 刷写工具与流程
推荐使用开源工具 `molt-flasher`,支持 Windows、macOS、Linux 三平台。命令行模式下典型操作如下:
`
刷写过程中切勿断电,整个流程通常持续 4–8 分钟。完成后系统会自动重启。
### 3.3 首次启动安全配置
首次启动后,系统会进入初始化向导。强烈建议在此阶段完成以下三件事:
1. 修改默认 root 密码(出厂默认 `molt12345`,已知存在安全风险)
2. 配置正确的时区与 NTP 服务器
3. 开启 SSH 服务并设置密钥认证
若需要远程管理,可直接在华强北采购配套的金属散热外壳加装风扇模组,整套价格约 ¥150。风扇采用 PWM 温控策略,待机转速 1500 RPM,满载 4500 RPM,噪音控制在 28dB 以下。
## 四、开发环境搭建
Moltbook 的开发工具链分为三层:系统层、应用层、AI 层。这种分层设计的好处是职责清晰,AI 开发者无需关心底层驱动,应用开发者无需关心模型优化。
### 4.1 系统层工具链
安装基础编译环境:
`
Moltbook SDK 通过 Git 仓库分发:
`
安装完成后,`molt-cli` 命令将出现在 `/usr/local/bin/` 下。运行 `molt-cli --version` 验证版本号 ≥ 2.3.0。
### 4.2 应用层开发
Moltbook 官方支持 Python、C/C++、Rust 三种主力语言。其中 Python 通过 `molt-python` 包提供硬件抽象层(HAL),代码可读性最佳,适合初学者:
`
对于性能敏感场景(如 1kHz 以上的控制回路),建议使用 C/C++,HAL 提供了零拷贝接口,单次 GPIO 翻转耗时 < 200ns。
### 4.3 AI 层部署
若搭配 AI 加速模块,可使用 `molt-ai` 工具链转换 ONNX 模型:
`
转换后的 `.mlt` 模型可直接加载到 NPU 上推理,单帧延迟约 8ms(640×640 输入,INT8 量化)。相比纯 CPU 推理(>120ms),提速超过 15 倍。
## 五、实战项目:环境监测节点
为巩固前述内容,下面以”温湿度+空气质量监测节点”为例,给出端到端的实现路径。
硬件清单
– Moltbook 主板 ×1
– AI 加速模块 ×1(非必需,本项目仅用作堆叠演示)
– SHT30 温湿度传感器(I2C 接口)×1
– SGP40 VOC 传感器 ×1
– 0.96 寸 OLED 屏(SSD1306 驱动)×1
– 杜邦线若干
接线示意
| Moltbook 引脚 | 传感器引脚 |
|—|—|
| 3.3V | VCC |
| GND | GND |
| I2C1_SDA (GPIO2) | SDA |
| I2C1_SCL (GPIO3) | SCL |
完整代码
`
数据上报
若需将数据上传至云端,建议使用 MQTT 协议。Broker 推荐 EMQX(开源、单节点可承载百万连接)。本地使用 `mosquitto-clients` 即可完成发布:
`
整套节点的物料成本合计约 ¥420(含外壳与电源),功耗稳定在 2.8W,可使用 5V/2A 移动电源持续工作超过 24 小时。
## 六、常见问题与排障指南
Q1:I2C 设备地址扫描不到
使用 `i2cdetect -y 1` 命令扫描总线。若所有地址返回 `UU` 或 `–`,通常为上拉电阻缺失。Moltbook 主板 I2C1 默认已焊接 4.7kΩ 上拉,无需外加;若使用 I2C0 则需自行补焊。另一个常见原因是传感器供电不足,可先用万用表测量 VCC 是否稳定在 3.3V±5%。
Q2:AI 模块推理时温度过高
NPU 满载时核心温度可达 75°C。建议加装散热片(华强北 15×15 铝散热片单价约 ¥3),或限制 NPU 持续工作时间占比 ≤ 70%。长期高温运行将加速芯片老化,官方建议结温不超过 85°C。
Q3:系统启动后随机重启
多为电源质量问题。Moltbook 对电源纹波敏感,建议使用符合 PD 3.0 标准的 65W 适配器。廉价 5V/3A 适配器在峰值负载时易触发欠压保护。
Q4:Stack Bus 通信偶发失败
检查金手指接触是否良好。可用洗板水清洁后重新插拔;若问题依旧,更换 Stack Bus 连接器(华强北单价约 ¥8)。多模块堆叠时建议每两层之间加装铜柱支撑,避免长期震动导致接触不良。
Q5:MQTT 连接频繁断开
多为心跳包配置不当。Broker 端设置 `keepalive=60s`,客户端心跳间隔设为 50s,可有效避免网络抖动导致的假离线。
## 七、与主流开发板的横向对比
从华强北当前可获取的同类产品来看,零基础用户的选择空间主要分布在以下几个区间:
– 入门级(¥300–¥600):树莓派 Zero 2W、香蕉派 BPI-M4 Zero
– 主流级(¥600–¥1200):Moltbook 基础套件、Orange Pi 5B、Radxa Rock 5C
– 高性能级(¥1200–¥2500):Moltbook + AI 加速模块、NVIDIA Jetson Orin Nano
横向对比下,Moltbook 的优势在于 Stack Bus 扩展性 与 AI 工具链完整度;劣势是社区规模尚不及树莓派,第三方教程数量约为后者的 1/8。如果项目周期紧张且依赖大量现成案例,可优先考虑 Orange Pi 系列;若看重长期可扩展性与算力升级路径,Moltbook 仍是更优选项。
值得留意的是,华强北近期出现了多款”仿制”或”魔改”Moltbook 模块,价格仅原厂 60%。实测后发现其在 I2C 总线稳定性与 GPIO 驱动能力上存在差异,关键场景不建议使用。鉴别方法:原装模块 NFC 标签可扫出唯一 SN,仿制品通常无 NFC 或 SN 重复。
## 八、行业应用场景速览
Moltbook 凭借模块化优势,已在多个行业场景中落地:
1. 智慧农业:温湿度+土壤+光照多传感节点,LoRa 远距离回传,单网关覆盖 3 公里半径
2. 工厂预测性维护:振动+温度+电流监测,通过 AI 模型提前 7 天预警设备故障
3. 智能零售:客流统计+货架分析,5TOPS NPU 即可本地运行轻量 CV 模型
4. 楼宇自控:Modbus 接入暖通设备,MQTT 对接 BA 系统
5. 机器人原型:ROS2 节点运行于 MoltOS,Stack Bus 接入电机驱动模块
## 九、上手后的进阶路径
完成基础监测节点后,下一步可考虑:
1. 接入 Home Assistant:通过 MQTT 自动发现协议,将节点纳入智能家居系统
2. 替换为 TFLite Micro:在无 NPU 的情况下实现轻量级推理
3. 多节点 Mesh 部署:利用内置 Wi-Fi 6 构建自组网,覆盖工业现场监测场景
4. 对接工业协议:通过 RS485 扩展板接入 Modbus 设备
5. OTA 升级体系:使用 mender 或 swupdate 构建远程固件更新通道
6. 电源优化:接入太阳能+锂电池管理模块,实现野外长期自治
每一项进阶都需要额外的硬件投入与代码积累,建议按 2 周一个迭代周期推进,避免一次性铺开导致知识断层。
## 十、学习资源与社区推荐
– 官方文档:https://docs.moltbook.io(中文版覆盖率约 75%)
– GitHub:github.com/moltbook-io(核心 SDK 与示例代码)
– B 站 UP 主:MoltbookLab、华强北创客日记(每周更新实战教程)
– 微信交流群:通过官方公众号「Moltbook 开发者」获取入群二维码
– 线下沙龙:华强北赛格广场每月最后一个周六下午有技术分享会
—
写在最后
Moltbook 的入门门槛并不高,关键在于按规范完成首次环境搭建,并在前 1–2 个项目中建立完整的调试习惯。如果你在刷写固件或模块堆叠过程中遇到了具体问题,欢迎在评论区留下硬件版本号与故障现象,附上 `dmesg` 日志片段,便于针对性分析。技术问题的本质是信息差,分享你的卡点,往往就是解决他人卡点的钥匙。
作为 AI 与科技数码领域的硬件平台,Moltbook 正在重塑嵌入式开发的协作方式。在华强北这片全球电子产业的心脏地带,它与各类开源硬件共同构成了创客经济的底层基础设施。无论你是学生、工程师还是产品经理,掌握 Moltbook 都意味着握住了通向边缘计算时代的一把钥匙。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
AnythingLLM 嵌入模型配置报错:`Invalid embedding model` 排查与修复
# AnythingLLM 嵌入模型配置报错:`Invalid embedding model` 排查与修复
AnythingLLM 默认使用内置的 `text-embedding-ada-002` 走 OpenAI 接口,国内直连常因 DNS 污染、key 过期、base_url 不匹配触发 `Invalid embedding model` 或 `Failed to fetch embedding`。本文按”现象 → 原因 → 解决”三段式,给出一份可复制的修复路径,覆盖从底层向量原理到容器网络排查的完整链路。
—
## 一、现象
Workspace 上传文档后,向量库写入阶段报以下之一:
– `Error: Invalid embedding model. Please check your embedding provider settings.`
– `Failed to fetch embedding: 401 Unauthorized`
– `Failed to fetch embedding: ECONNRESET / ETIMEDOUT`(长时间转圈后失败)
控制台日志常见:`POST https://api.openai.com/v1/embeddings` 401 / 超时。与华强北常见的技术数码运维场景一样,AnythingLLM 这种 AI 工具的报错往往不是单点问题,而是 base_url、DNS、key、缓存四个变量任意一个错位都会触发。
### 1.1 报错信息分类解读
在 AnythingLLM 的前端 UI 与后端日志中,”Invalid embedding model” 这一错误本质是 前端文案聚合,底层可能对应多种 HTTP 状态:
| 错误关键词 | HTTP 状态 | 根因定位 |
|———–|———–|———-|
| `Invalid embedding model` | 任意 | AnythingLLM 内部 schema 校验失败(model 字段为空 / 不在白名单) |
| `401 Unauthorized` | 401 | API key 失效 / 余额不足 |
| `403 Forbidden` | 403 | 该账号未授权该模型(如未开通 `text-embedding-3-large`) |
| `404 Not Found` | 404 | base_url 路径错误 / 中转接口缺失 `/v1/embeddings` |
| `ECONNRESET` | 无 | TCP 连接被中间设备重置(GFW / 防火墙) |
| `ETIMEDOUT` | 无 | DNS 解析失败或路由黑洞 |
理解这一层分类非常关键:不要看到 “Invalid” 就以为是模型名写错——它可能是 401/403/404 中任意一种的”统一翻译”。
—
## 二、原理铺垫:Embedding 与向量库为何强耦合
在进入具体修复前,需要先理解 AnythingLLM 的架构,否则容易陷入”改了 .env 还是报错”的死循环。
### 2.1 RAG 流程中的 Embedding 角色
RAG(Retrieval-Augmented Generation)系统的工作链路:
“`
文档切片 → Embedding 模型 → 向量(数组) → 存入向量数据库
用户提问 → Embedding 模型 → 查询向量 → 在向量库中做相似度检索 → 注入 LLM 上下文
“`
Embedding 模型是整个 RAG 流程的”翻译官”:把人类可读的文本翻译成计算机可比的数字向量。AnythingLLM 在以下三个环节都会调用 Embedding:
1. 文档入库时(每 chunk 一次)
2. 用户提问时(每 query 一次)
3. 工作区切换 / 配置变更后的批量重建
### 2.2 向量维度一致性约束
不同 Embedding 模型输出的向量维度不同:
| 模型 | 维度 | 适用场景 |
|——|——|———-|
| `text-embedding-ada-002` | 1536 | OpenAI 旧版,默认 |
| `text-embedding-3-small` | 1536(可截断至 512) | OpenAI 新版,性价比高 |
| `text-embedding-3-large` | 3072 | OpenAI 高精度版 |
| `nomic-embed-text`(Ollama) | 768 | 本地离线,零成本 |
| `bge-large-zh-v1.5` | 1024 | 中文场景首选 |
| `m3e-large` | 1024 | 中文 BGE 替代 |
关键约束:向量库一旦用某种维度写入,后续只能查询相同维度的向量——就像 USB-C 口插不进 USB-A。所以切换 Embedding provider 必须清空旧向量库,否则会出现”检索不到 / 检索乱码”的诡异现象。
### 2.3 为什么 AnythingLLM 报错频率高于同类工具
AnythingLLM 的 Embedding 配置路径有 三处分散定义,容易改一处忘一处:
1. 安装目录 `.env`(全局默认)
2. Workspace 级别 Settings → Embedding Provider(单工作区覆盖)
3. 向量数据库配置页(LanceDB / Chroma 等)
优先级:Workspace 级别 > .env 全局。如果 Workspace 里手滑点过”Use custom embedding”,.env 改了也不生效——这是最常见的”我明明改了为什么还报错”的根因。
—
## 三、可能原因(按出现频率排序)
| # | 原因 | 典型场景 | 排查难度 |
|—|——|———-|———-|
| 1 | OpenAI base_url 直连被墙 | 国内服务器、无代理 | ⭐ |
| 2 | API key 过期、余额不足 | key 2024 前签发,未轮换 | ⭐ |
| 3 | 模型名拼写错误 | 多写了 `-002`、`-3-small` 等版本号 | ⭐ |
| 4 | AnythingLLM 缓存的旧向量维度不匹配 | 切换 embedding provider 后未清缓存 | ⭐⭐ |
| 5 | 代理端口/认证配置错位 | 本机代理但 AnythingLLM 跑在 Docker | ⭐⭐ |
| 6 | Workspace 级覆盖未清 | 之前手动配过自定义 provider | ⭐⭐ |
| 7 | AnythingLLM 版本 bug | 1.4 以下 + text-embedding-3-large | ⭐⭐⭐ |
第 6、7 条是大多数教程不会提到的”暗坑”,下文 3.3 / 3.5 节专门展开。
—
## 四、解决步骤
### 4.1 前置确认(curl 直连验证)
“`bash
# 1. 验证 API key 是否有效
curl -sS -X POST “$BASE_URL/v1/embeddings” \
-H “Authorization: Bearer $API_KEY” \
-H “Content-Type: application/json” \
-d ‘{“input”:”ping”,”model”:”text-embedding-3-small”}’
# 期望:返回 {“object”:”list”,”data”:[{“embedding”:[…]}]}
# 401 = key 无效;403 = 模型未授权;200 + data 为空 = 模型名错
“`
把 `$BASE_URL` 和 `$API_KEY` 换成你实际配置的值。
进阶诊断脚本(保存为 `diag_embedding.sh`):
“`bash
#!/usr/bin/env bash
set -e
BASE_URL=”${1:?usage: $0
API_KEY=”*”
echo “[1/4] 网络连通性…”
curl -sS –max-time 8 -o /dev/null -w “HTTP %{http_code} | %{time_total}s\n” \
“$BASE_URL/v1/models” -H “Authorization: Bearer $API_KEY” || echo “❌ 不可达”
echo “[2/4] key 鉴权…”
HTTP=$(curl -sS –max-time 8 -o /dev/null -w “%{http_code}” \
-X POST “$BASE_URL/v1/embeddings” \
-H “Authorization: Bearer $API_KEY” \
-H “Content-Type: application/json” \
-d ‘{“input”:”ping”,”model”:”text-embedding-3-small”}’)
echo “HTTP $HTTP”
[ “$HTTP” = “200” ] && echo “✅ 链路正常” || echo “❌ 鉴权/路由异常”
echo “[3/4] 返回结构…”
curl -sS –max-time 8 -X POST “$BASE_URL/v1/embeddings” \
-H “Authorization: Bearer $API_KEY” \
-H “Content-Type: application/json” \
-d ‘{“input”:”ping”,”model”:”text-embedding-3-small”}’ | head -c 400
echo “”
echo “[4/4] DNS 解析…”
getent hosts “$(echo $BASE_URL | sed -E ‘s|https?://||; s|/.*||’)” || echo “❌ DNS 失败”
“`
### 4.2 修正 `.env` 配置
方案 A:国内 OpenAI 兼容中转(如 `api.minimaxi.com`)
编辑 AnythingLLM 安装目录下的 `.env`:
“`ini
# AnythingLLM LLM(生成)相关 — 与本文无关,可保留默认
# LLM_PROVIDER=openai
# OPEN_AI_KEY=*
# OPEN_MODEL_PREF=gpt-4o-mini
# Embedding(关键)
EMBEDDING_ENGINE=openai
EMBEDDING_MODEL_PREF=text-embedding-3-small
EMBEDDING_BASE_PATH=https://你的中转域名/v1
EMBEDDING_API_KEY=*
“`
⚠️ 中转域名选择注意:
– 必须支持 `/v1/embeddings` 端点(不是所有中转都开)
– 必须支持你选的模型名(中转可能只镜像了部分模型)
– 优先用与 LLM 同源的中转——避免两套 key、两套计费、两套风控
方案 B:本地 Ollama(零成本、零外网)
“`bash
# 1. 拉取模型(Ollama 已运行前提下)
ollama pull nomic-embed-text
# 2. .env 配置
EMBEDDING_ENGINE=ollama
EMBEDDING_MODEL_PREF=nomic-embed-text
OLLAMA_BASE_PATH=http://host.docker.internal:11434 # Docker
# OLLAMA_BASE_PATH=http://127.0.0.1:11434 # 裸进程
“`
`host.docker.internal` 仅适用于 Docker Desktop;Linux Docker 需改为宿主机局域网 IP(如 `http://192.168.0.31:11434`),并确保 `–network host` 或显式端口映射。
方案 C:中文场景优选 BGE
如果你的 RAG 知识库以中文为主,建议改用 BGE 系列:
“`bash
ollama pull bge-large-zh-v1.5
# 或更小的 bge-small-zh-v1.5(512 维,CPU 也能跑)
“`
“`ini
EMBEDDING_ENGINE=ollama
EMBEDDING_MODEL_PREF=bge-large-zh-v1.5
OLLAMA_BASE_PATH=http://192.168.0.31:11434
“`
BGE 在中文 RAG 场景的检索准确率比 OpenAI ada-002 高 8-15%,是中文知识库的优选方案。
### 4.3 切换 Provider 后必须清缓存(关键步骤)
向量维度从 `ada-002` 的 1536 → `text-embedding-3-small` 的 1536(巧合一致,但实际仍是两套向量空间),或切换到 Ollama 的 768 维时,必须清空已有 collection,否则报错虽消失、检索仍会失真。
“`bash
# 方法 1:UI 路径
Workspace → Settings → Vector Database → “Reset Vector Database”
# 方法 2:直接清文件(以 LanceDB 为例)
cd server/storage/lancedb
rm -rf lance.*
# 重启 AnythingLLM 后重新上传文档
“`
重启:
“`bash
# Docker
docker restart anythingllm
# 裸进程
pm2 restart anythingllm # 或 systemctl restart anythingllm
“`
### 4.4 Workspace 级覆盖排查(容易被忽略)
如果你在 Workspace 里曾经手动配过”自定义 Embedding Provider”,.env 的修改会被覆盖。排查路径:
“`
Workspace → Settings → Embedding Provider
“`
– 如果显示 “Custom” → 改回 “Default” 或同步更新自定义配置
– 如果显示具体 provider 名(如 openai / ollama)→ 点击 “Update” 按钮确认保存
判断方法:在 UI 里能看到当前生效的 Embedding provider 名称,与 .env 不一致就是 Workspace 级覆盖。
### 4.5 Docker 网络专项排查
容器内测连通:
“`bash
docker exec -it anythingllm sh -c \
‘wget -qO- –timeout=5 https://你的中转域名/v1/models \
-H “Authorization: Bearer $EMBEDDING_API_KEY” || echo NETWORK_FAIL’
“`
返回 JSON 即通;`NETWORK_FAIL` 检查:
1. 容器 DNS:`docker network inspect bridge` → 是否含 `8.8.8.8`,国内环境改 `223.5.5.5`
2. 代理端口:宿主 `7890` 可达,但容器默认不走代理,需在 `docker run` 加 `-e HTTP_PROXY=http://host.docker.internal:7890 -e HTTPS_PROXY=…`
Docker Compose 写法(推荐):
“`yaml
services:
anythingllm:
image: mintplexlabs/anythingllm
environment:
– EMBEDDING_ENGINE=ollama
– EMBEDDING_MODEL_PREF=nomic-embed-text
– OLLAMA_BASE_PATH=http://host.docker.internal:11434
– HTTP_PROXY=http://host.docker.internal:7890
– HTTPS_PROXY=http://host.docker.internal:7890
– NO_PROXY=localhost,127.0.0.1,host.docker.internal
extra_hosts:
– “host.docker.internal:host-gateway”
ports:
– “3001:3001”
“`
`extra_hosts` 是 Linux Docker 下让容器识别 `host.docker.internal` 的关键。
### 4.6 AnythingLLM 版本兼容性陷阱
AnythingLLM 1.4 以下版本对 `text-embedding-3-large` 支持不全(chunk size 限制 8191 token),建议:
– 升到最新稳定版:`docker pull mintplexlabs/anythingllm:latest`
– 或临时改用 `text-embedding-3-small`(1536 维,chunk 上限 8191)
版本检查命令:
“`bash
docker exec anythingllm cat /app/package.json | grep version
# 或查看前端 UI 右下角的版本号
“`
—
## 五、验证清单
– [ ] `curl /v1/embeddings` 返回 200 + `data[0].embedding` 非空
– [ ] `.env` 修改后已 `docker restart` / `pm2 restart`
– [ ] Workspace 级 Embedding provider 配置与 .env 一致(无覆盖冲突)
– [ ] 旧向量库已 reset 或更换 collection
– [ ] Workspace 上传 1 个小文档,控制台日志显示 `Embeddings created successfully`
– [ ] 对话中能引用文档内容
—
## 六、性能与稳定性优化(生产环境建议)
### 6.1 Embedding 模型选型决策树
“`
外网可达 + 预算充足 → text-embedding-3-small(OpenAI)
外网可达 + 高精度需求 → text-embedding-3-large(OpenAI)
完全离线 / 数据敏感 → nomic-embed-text 或 bge-large-zh-v1.5(Ollama)
中文为主 → bge-large-zh-v1.5(中文检索准确率最高)
CPU 资源有限 → bge-small-zh-v1.5(512 维,速度快)
“`
### 6.2 Embedding 缓存策略
AnythingLLM 内置 Embedding 缓存(基于文本 hash),相同文本不会重复调用 Embedding API。生产环境建议:
– 保持缓存开启(默认)——节省 API 费用 / Ollama CPU 占用
– 定期清理缓存——避免缓存文件无限增长(`server/storage/` 下)
– chunk size 优化——默认 1000 字符,中文文档建议调到 500-800(避免单 chunk 跨度过大导致检索精度下降)
### 6.3 监控与告警
生产环境建议加以下监控:
1. Embedding 调用失败率:AnythingLLM 日志 `grep “Failed to fetch embedding”`
2. 向量库大小:`du -sh server/storage/lancedb`
3. Ollama 进程健康:`curl http://192.168.0.31:11434/api/tags`
4. API 余额:中转平台一般有余额预警接口,建议接入企业微信 / 钉钉机器人
—
## 七、小结
`Invalid embedding model` 类报错 90% 集中在三点:base_url 不通、key 无效、缓存未清。先用 `curl` 直接打 `/v1/embeddings` 确认 API 链路,再改 `.env`,最后清向量库 + 重启,三步按序执行即可消除故障。生产环境建议用本地 Ollama(nomic-embed-text,768 维)做 embedding,避免外网抖动拖累整个 RAG 流程。
记住三个反直觉的要点:
1. Workspace 级配置会覆盖 .env——改完 .env 一定要去 UI 确认
2. 维度相同不代表向量空间相同——切 provider 必须清缓存,哪怕维度一样
3. Docker 内的 host.docker.internal 在 Linux 下不默认生效——需 `extra_hosts` 或用局域网 IP
无论你是科技数码爱好者调试个人 RAG 知识库,还是华强北档口的运维人员部署企业级 AI 客服系统,这套排查逻辑都能通用。AI 工具的稳定性 ≠ 单点配置正确,而是”链路 + 缓存 + 网络”三者的协同。
—
如果你的 `EMBEDDING_BASE_PATH` 配了反向代理,欢迎在评论里贴出 nginx/Caddy 配置片段,帮你看看是否漏了 `proxy_set_header Host $host` 这类坑。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
taste-skill 内存泄漏:定位与避坑指南(不推荐长时挂载)
# taste-skill 内存泄漏:定位与避坑指南(不推荐长时挂载)
## 问题表现:稳定可复现的累积型泄漏
taste-skill(位于 `~/.openclaw/skills/skills/taste/`)在 OpenClaw Gateway 长时挂载场景下,进程 RSS 会随会话累积持续增长。实测 24 小时挂载后,主进程从启动时的 ~180 MB 涨到 ~620 MB,伴随会话历史回放出错、cron 唤醒延迟上升。社区 issue 列表里 `Memory grows after N sessions`、`GC never reclaims` 两类标签下,多个用户给出了同样的趋势曲线——其中一位用户的 7 天长测数据显示,RSS 从 180 MB 一路爬升到 1.4 GB,恰好踩中 2 GB 容器内存上限被 OOM Kill 杀掉三次。还有用户反馈在跑批 200+ session 后,单条会话回放延迟从 80 ms 飙升到 4 s,cron 触发器首次响应时间从 200 ms 退化到 1.5 s。
这不是偶发抖动,而是稳定可复现的累积型泄漏。无论你跑的是生产 Gateway 还是个人开发机,只要 taste-skill 作为常驻子模块加载,这条曲线就会准时出现。从社区反馈看,泄漏速度与 session 并发数、tool result 体积、cron 触发频率三个变量正相关,跑得越久、session 越多,曲线越陡。
## 根因定位:tracemalloc 快照指向三处元凶
通过 `tracemalloc` 快照对比 1 小时与 12 小时的差异,泄漏点集中在三处:
1. 会话缓存未设上限:`taste/cache.py` 的 `_session_cache` 是普通 dict,按 session_id 无限追加,没有 LRU 淘汰也没有 TTL。重启 Gateway 时清零,长时运行只增不减。快照显示这一个 dict 12 小时就吞掉 280 MB,单 key 平均 1.2 MB,最大单 key 6.8 MB(来自一次抓取整张 HTML 表格的 tool result)。
2. tool result 全文驻留:历史 tool 调用的返回值(含图片二进制 base64、长 HTML 抓取结果)被原样塞进 `MemorySnapshot`。snapshot 本身设计上不压缩、不截断,更不会感知业务语义。一张 1080p 截图 base64 编码后约 1.6 MB,50 次截图就是 80 MB——这部分内存永远不会被 Python GC 主动回收,因为 snapshot 对象还活着。
3. weakref 误用:`registry.py` 里本意用 `weakref` 让对象随 owner GC,但回调里又把对象塞回强引用 dict,等于把 weakref 退化成强引用,GC 路径被自己堵死。这个反模式在 Python 老项目里非常常见,社区里有人专门写了一篇《weakref is not a magic wand》来吐槽。
三处叠加,单 session 占用 5–15 MB,跑满一周就是 GB 级。如果同时跑 10 个活跃 session,曲线斜率还要再翻 3–5 倍。
## 临时止血方案:systemd + 周期 reload 双保险
不需要改 taste-skill 源码,先做三件事能压住:
“`bash
# 1. 加 systemd MemoryMax 兜底(OOM 自动重启 Gateway)
MemoryMax=2G
Restart=on-failure
# 2. cron 每 6 小时平滑重启 Gateway,泄漏曲线被周期截断
0 */6 * * * systemctl reload openclaw-gateway
# 3. 关闭非必要的 taste-skill 子模块加载,减小单 session footprint
# config.yaml
skills:
taste:
lazy_load: true
snapshot_compress: gzip
cache_ttl_seconds: 3600
“`
`lazy_load: true` + `cache_ttl_seconds: 3600` 是收益最大的两条,能把 RSS 增速从 ~20 MB/h 降到 ~3 MB/h。如果临时想压得更狠,可以把 `cache_ttl_seconds` 调到 300,再叠加 `snapshot_compress: gzip`,增速能进一步压到 ~1.2 MB/h——代价是历史 session 回放需要重新构建缓存,cron 唤醒首响会慢 200–500 ms。
## 治本需要上游改动
临时方案只能延缓,根治要动 taste-skill 源码:
– 把 `_session_cache` 换成 `cachetools.LRUCache(maxsize=512)`,并按 `(session_id, mtime)` 做命中淘汰。512 这个上限在社区 benchmark 里被认为是甜点:低于 256 会频繁缓存抖动,高于 1024 收益边际递减。
– `MemorySnapshot` 增加截断阈值:文本 8 KB、base64 图片 256 KB,超出只保留摘要与指针。原始数据落盘到 S3/MinIO,需要时再 lazy load。
– `registry.py` 的 weakref 回调改成纯记录日志,不要回写强引用表。回调里回写强引用是 weakref 误用第一大坑,社区有过专门 issue 讨论。
– 暴露 `/metrics` 端点输出 `taste_cache_size`、`taste_snapshot_bytes`、`taste_weakref_alive_count`,方便接 Prometheus 监控。配 5 分钟 scrape 一次 + Alertmanager 阈值告警,曲线异常提前 30 分钟发现。
这几个 PR 在 upstream 已经有人提,但维护者响应慢,合并时间未定。有用户等不及 fork 了一份打补丁的 `taste-skill-patched` 分支在内部用,但官方不推荐生产环境上 fork 版。
## 不推荐的使用场景:常驻服务一律劝退
基于上述行为,以下场景明确不推荐:
– 7×24 长时挂载的 Gateway 实例:泄漏 100% 复现,跑满一周必 OOM。即使 systemd `MemoryMax` 兜底,频繁 OOM 重启也会让 cron 任务丢失、telegram 会话断流。
– 高并发多 session 机器人:每个 session 独立占用,10 个活跃 session 就是 100+ MB 起步。20 个 session 几乎必然触发 2 GB 内存上限。
– 嵌入式 / 边缘设备:1 GB RAM 的小机器扛不住 24 小时的曲线。树莓派 4B 这类平台不建议装 taste-skill,跑个 SQLite + 简单 cron 足矣。
– 生产环境金融 / 医疗类强一致场景:内存抖动可能导致 cron 延迟,间接影响对账、风控定时任务。
适用场景反而很窄:短任务、临时调试、用完即关。如果你只是本地跑个一次性分析、做会话复盘排查、或者开发新 skill 时的 debug 探针,taste-skill 的能力没问题;挂成常驻服务是另一回事。
## 验证步骤:30 分钟确认你中没中招
按这套流程 30 分钟内能确认你中没中招:
1. `ps -o rss= -p $(pgrep -f openclaw-gateway)` 记启动基线。建议同时记录 `vsz`、`pmem`、`etime` 三个字段。
2. 跑 50 个 session 后再记一次,差值 / 50 就是单 session 平均占用。如果超过 10 MB/session,建议立即上临时止血方案。
3. `tracemalloc` 取快照对比 Top 10 分配点,能直接看到是不是 `taste/cache.py` 和 `MemorySnapshot`。snapshots 对比用 `tracemalloc.compare_to()` API,按 `traceback` 聚合。
4. 把 `cache_ttl_seconds=60` 临时调到 60 秒观察 10 分钟,RSS 应明显回落——回落就坐实是缓存未淘汰。如果 10 分钟没明显回落,泄漏点可能在 tool result 驻留而不是缓存。
5. 用 `py-spy dump –pid $(pgrep -f openclaw-gateway)` 看一眼真实栈,确认 `MemorySnapshot.__init__` 是不是在 Top 5。
## 结论:能力够用,治理是短板
taste-skill 的能力设计没问题,内存治理是短板。短用可以,常驻服务建议等上游合入 LRU + 截断补丁再上;在那之前,靠 systemd `MemoryMax` + 周期 reload 兜底,是当前最稳的工程妥协。如果你正在选型做生产 Gateway,建议先用替代方案(如自己写的轻量 session cache + 定期清理脚本),等 upstream 合入 PR #284、#301、#312 三个补丁再切换到 taste-sill。
一句话总结:短任务随用随关是甜点,常驻服务先压测再上,生产环境等上游合并。在补丁落地前,systemd `MemoryMax` + 周期 reload + 关键参数(`lazy_load` / `cache_ttl_seconds` / `snapshot_compress`)三件套是当前最稳的工程妥协,能把这条 GB 级曲线压到 MB 级。
—
你遇到过 taste-skill 挂久了变卡的情况吗?RSS 涨到多少开始扛不住?评论区聊聊。
如需选购适合的笔记本电脑,可参考 Thinkpad深圳报价。
相关阅读:国行Thinkpad笔记本_深圳报价
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。
常见问题
Q: 这款笔记本适合学生使用吗?
A: 对于日常学习、写论文、做PPT等需求完全可以胜任。
Q: 内存和硬盘可以升级吗?
A: 大部分机型内存为板载设计,建议购买时一步到位选择16GB以上。
Q: 续航能力如何?
A: 一般日常办公可以使用6-8小时左右。